Protocol Specification
Mesh Memory Protocol (MMP) v1.0.3
A Mesh Protocol for Collective Intelligence
Canonical: meshcognition.org/spec/mmp · arXiv: 2604.19540
Overview
Protocol Specification
Mesh Memory Protocol (MMP)
A Mesh Protocol for Collective Intelligence
| Version | 1.0.3 |
| Status | Published |
| Date | 27 April 2026 |
| Author | Hongwei Xu <editor@meshcognition.org> |
| Organisation | SYM.BOT |
| Canonical URL | https://meshcognition.org/spec/mmp |
| Licence | CC BY 4.0 (specification text); Apache 2.0 (reference implementations) |
Introduction
Multi-agent LLM systems in production coordinate cognitive work on shared tasks spanning hours, days, and weeks — generator/quality/auditor pipelines running for days; research investigations spanning weeks across session restarts; a coding agent, a music agent, and a fitness agent serving the same user where no single agent connects “commits slowing” + “tracks skipped” + “3 hours without movement” into “the user is fatigued.” That insight requires structured collective intelligence — and the semantic-integration layer of agent communication is, today, unaddressed.
Existing protocols at lower layers standardize tool access and task delegation between agents. What each receiver does with incoming observations from a peer — per-field admission, signal-level lineage, filtering at acceptance time — is the missing layer. The Mesh Memory Protocol specifies that layer through four composable primitives: CAT7, a fixed seven-field schema for every Cognitive Memory Block; SVAF, per-field admission against the receiver’s role-indexed anchors; content-hash lineage, so every claim is traceable to its source observation; and remix, where receivers store only their own evaluated understanding of accepted blocks, never raw peer signals.
The problem is semantic, not transport. Hidden state never crosses the wire — each agent’s learned cognition stays sovereign on its own device; only Cognitive Memory Blocks (CMBs) propagate. Receiver-autonomous admission lets the mesh grow without re-introducing a master — same reason TCP/IP beat circuit-switching. MMP defines transport over TCP on local networks and WebSocket for internet relay, with length-prefixed JSON as the canonical wire format. Discovery uses DNS-SD (Bonjour) with zero configuration. The protocol is specified across 8 layers — from identity and transport (Layers 0–3), through cognitive coupling via SVAF (Layer 4), to synthetic memory and per-agent neural networks (Layers 5–7). Together, the upper layers form Mesh Cognition: a closed loop where agents reason on the growing remix graph of immutable Cognitive Memory Blocks.
Status of This Document
This is a published specification (current version 1.0.3). It reflects the protocol as implemented in the SYM Node.js and SYM Swift full-stack reference implementations, plus the mesh-cognition Python coupling kernel (Layers 4 + 6). The specification is versioned. Breaking changes increment the minor version; non-breaking additions increment the patch version.
Feedback and errata: spec@meshcognition.org or github.com/sym-bot/sym/issues.
Implementations
| Language | Project | Maintainer | Scope |
|---|---|---|---|
| Node.js / TypeScript | sym-bot/sym | SYM.BOT | Reference implementation. Full protocol surface (Layers 0–7). |
| Swift | sym-bot/sym-swift | SYM.BOT | Reference implementation. macOS / iOS. Full protocol surface. |
| Python | sym-bot/mesh-cognition | SYM.BOT | Coupling kernel only. Layer 4 (per-field admission) and Layer 6 (Cognitive State) for CfC neural networks. Pure Python, zero external dependencies. pypi. |
Change Log
| Version | Date | Changes |
|---|---|---|
| 1.0.3 | 2026-06-16 | §15.7.1 Source-Novel Forwarding — carve-out distinguishing forwarding from the remix-paraphrase §15.7 forbids. An agent MAY re-emit an admitted observation it did not natively produce, carrying the inherited lineage root, when and only when that observation is source-novel to the receiver — its lineage roots are not already present in the receiver’s admitted store. This is not the value-only echo §15.7 prevents: a forwarded observation carries a source the receiver has not yet seen even though the forwarder adds no new domain data. Forwarding MUST NOT mint a fresh root for content that already carries one, and MUST NOT re-emit a source the receiver already holds — the anti-echo guarantee is preserved exactly. Forwarding SHOULD be non-selective, so every observation reaches the agents whose understanding depends on it. In short: remix requires new domain data; forwarding requires a new source. Backward-compatible addition (patch). |
| 1.0.2 | 2026-06-14 | §2.7 Hidden State Locality — states the invariant that a node’s hidden state (its Layer 6 LNN vectors h₁/h₂) MUST remain strictly local and MUST NOT cross the wire; only Cognitive Memory Blocks cross. Defines hidden state (private machinery) vs. the remixed CMB (communicable understanding), and the four reasons hidden state must stay local: sovereignty, auditability, semantic incompatibility across agents, and privacy. Supersedes the state-sync model: the state-sync frame and any exchange of h₁/h₂ vectors are deprecated; the peer-drift and state-blending mechanisms described in §5, §7, §9.1, and §10 from exchanged hidden-state vectors are superseded — peer influence is mediated entirely by CMBs evaluated through SVAF (§9.2). Resolves a self-contradiction between the “hidden state never crosses the wire” claim and the state-sync sections. |
| 1.0.1 | 2026-06-12 | Layer 6 renamed “xMesh” → “Cognitive State” to disambiguate from the xMesh runtime (naming note §1, §13; wire identifiers incl. xmesh-insight unchanged; published papers retain the legacy “xMesh (L6)” label). Normative additions, backward-compatible with the v1.0 contracts: §9.2.1 specifies δf as an admission interface — anchors-only baseline (incoming block excluded), cold-start non-evaluable-field exclusion + bootstrap-admit — ruling out self-referential collapse and cold-start starvation. §9.2.2 specifies the directed (peer-bound) vs autonomous (group-bound) delivery contract, separating delivery from memory admission: directed CMBs (§4.4.4 to = receiver) surface unconditionally; rejected broadcasts do not surface (mood excepted, §9.3). §18.3.1 specifies CMB signature verification (Ed25519 author signature + content-address integrity; forged/tampered blocks rejected) as the end-to-end authenticity layer above transport identity. |
| 1.0 | 2026-04-27 | Public-stable-API release. Marks the v0.2.x development cadence as complete and the protocol surface as production-stable. Contracts unchanged from 0.2.3; v0.2.x → v1.0 is a maturity declaration, not a breaking change. Note: arXiv:2604.19540 cites v0.2.x as the version implemented at paper-publication time; v1.0 covers the same contracts. |
| 0.2.3 | 2026-04-17 | Section 13.9 — Compact Channel Best Practices: CMB envelope header convention (RECOMMENDED) for structured message headers with signal keywords and focus tags. Lazy-load channel pattern (RECOMMENDED) for MCP server implementations: compact header push with on-demand full-content retrieval via sym_fetch, reducing mesh-traffic context consumption by ~75%. Token-count hint RECOMMENDED. Rolling message store with RECOMMENDED default of 200 messages. Signal-keyword priority table (informational): HALT > DIRECTIVE > RESULT > ACK. |
| 0.2.2 | 2026-04-06 | Section 11 — Feedback Modulation: how collective intelligence becomes self-correcting. Validator-authority CMBs with per-field reasoning modulate SVAF coupling weights and CfC temporal adaptation through the existing mesh cognition loop. Neuroscience-grounded: dopaminergic prediction error model with per-field direction and τ-modulated adaptation rate. Directive feedback for standalone domain knowledge injection. Validator-origin anchor weight 2.0 with role-grant verification. CfC state persistence across restarts. ABNF wire format grammar. CMB forward compatibility. Multi-relay failover. All cognitive content MUST use cmb frames. |
| 0.2.1 | 2026-04-02 | Node model: every autonomous agent MUST be a full peer node with own identity, coupling engine, and memory store. SVAF band-pass evaluation: four-class model (redundant/aligned/guarded/rejected) with per-field redundancy detection. CMB lifecycle: observed/remixed/validated/canonical/archived with anchor weight progression. Node lifecycle roles (observer/validator/anchor) with identity-bound validation authority and earned role progression. Validation authority for CMB lifecycle transitions bound to cryptographic node identity, not content. Semantic encoder SHOULD for SVAF drift computation. Handshake adds version, extensions, and lifecycleRole fields. Error frame type. Role-grant frame type. |
| 0.2.0 | 2026-03-27 | Formal specification published. 8-layer architecture. CAT7 CMB schema with lineage (parents + ancestors). SVAF per-field evaluation. Wire format normatively specified. Error frame. Frame type registry. Extension mechanism. JSON Schema. Connection state machine. Wire examples. |
| 0.1.0 | 2025-08-01 | Initial protocol design (Consenix Labs Ltd). 4-layer architecture. Scalar drift evaluation. |
Licence
This specification is published under the Creative Commons Attribution 4.0 International Licence (CC BY 4.0). You may share, adapt, and build upon this specification for any purpose, including commercial use, provided you give appropriate credit.
The reference implementations are published under the Apache Licence 2.0.
SYM and SYM.BOT are trademarks of SYM.BOT. The Mesh Memory Protocol is published under CC-BY-4.0; the term "Mesh Cognition" is intentionally unmarked — the open-protocol category is free vocabulary.
© 2026 SYM.BOT. Specification text licenced under CC BY 4.0. Reference implementations licenced under Apache 2.0.
1. Conventions
1. Conventions and Terminology
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC 2119.
Naming note
Layer 6 was called xMesh in the v0.2.x drafts and in the published papers
(arXiv:2604.19540,
arXiv:2604.03955).
As of v1.0.1 the layer is named Cognitive State; xMesh now refers exclusively to the open
runtime that implements MMP (all eight layers). The wire frame type
xmesh-insight retains its identifier for backward
compatibility and is unchanged.
| Term | Definition |
|---|---|
| Node | A participant in the mesh. Every node has a unique identity, its own coupling engine, and its own memory store. Cognitive nodes run their own LNN; relay nodes forward frames without cognitive processing. |
| Peer | Another node that this node has an active transport connection with and has completed a handshake. |
| Frame | A single protocol message: a length-prefixed JSON object sent over a transport connection. |
| CMB | Cognitive Memory Block — a structured memory unit with 7 typed semantic fields (CAT7 schema). See Section 8. |
| Drift | A scalar measure of cognitive distance between two nodes or between a signal and local state. Range [0, 1]. |
| Coupling | The process by which a node evaluates incoming signals (SVAF per-field evaluation) and blends its local cognitive state with peer state, weighted by drift and confidence. |
| SVAF | Symbolic-Vector Attention Fusion — per-field content-level evaluation of incoming memory signals. See Section 9. |
| Synthetic Memory | Layer 5 — derived knowledge generated by the agent’s LLM reasoning on the remix subgraph, encoded into CfC-compatible hidden state vectors. |
| Remix | When an agent processes a CMB through its domain intelligence and produces a NEW CMB with lineage pointing to the original. The original is remixed, not copied. |
| Lineage | Each CMB carries parents (direct) and ancestors (full ancestor chain). Ancestors enable any agent in the remix chain to trace its contribution. |
| Mesh Cognition | The agent’s LLM reasoning on the remix subgraph of CMBs — traced via lineage ancestors — to generate understanding that the agent’s previous state of mind didn’t have. Spans Layers 4–7. See Section 2.5. |
| Cognitive State | Layer 6 — each agent’s own Liquid Neural Network (LNN). Evolves continuous-time cognitive state from Synthetic Memory input. Fast τ neurons track mood; slow τ neurons preserve domain expertise. (Called xMesh in v0.2.x drafts and the published papers — see the §1 naming note.) |
| CfC | Closed-form Continuous-time neural network (Hasani et al., 2022). The LNN architecture used in the Cognitive State layer. Hidden state evolves through learned time-dependent interpolation gates. |
2. Architecture
2. Architecture Overview
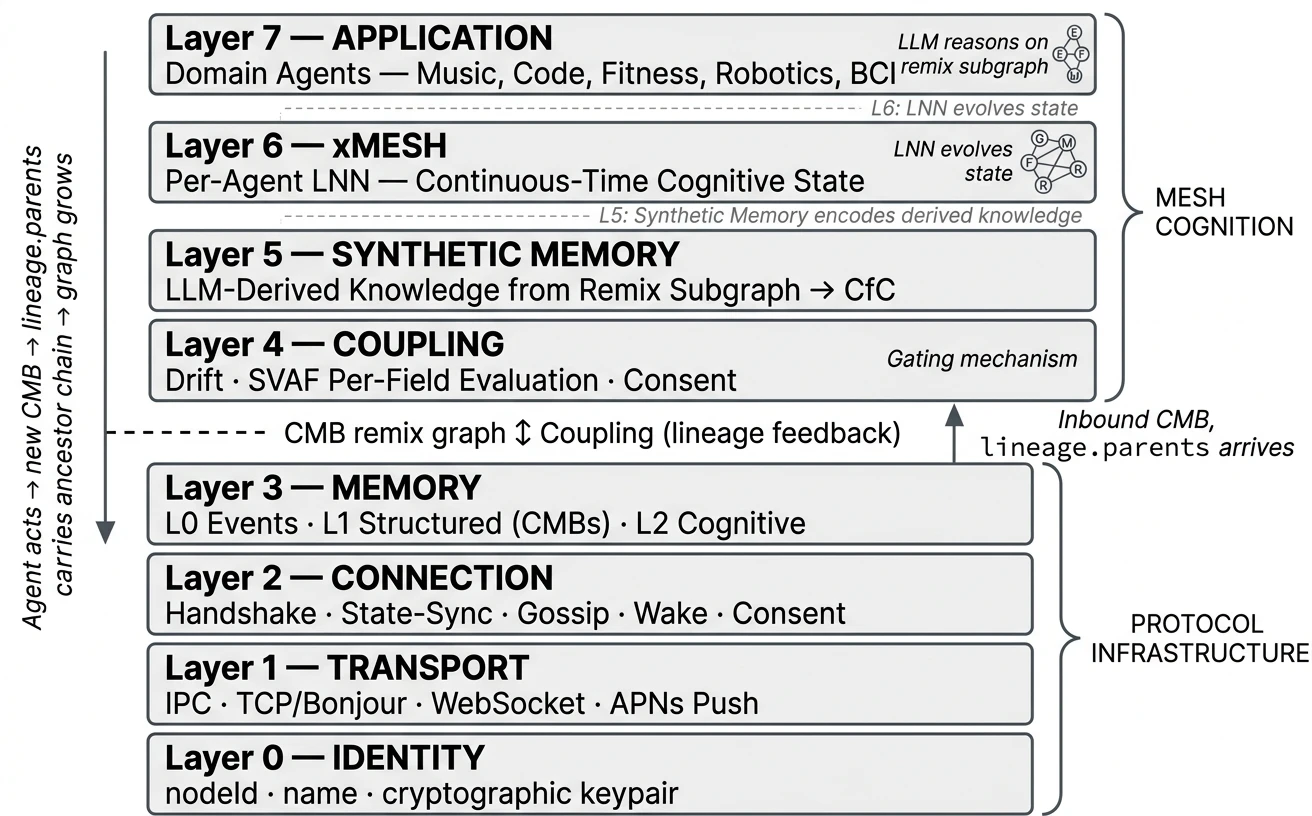
MMP is an 8-layer protocol stack. Each layer has a defined responsibility. Implementations MUST implement Layers 0–3 to participate in the mesh. Layers 4–7 (Mesh Cognition) are SHOULD for full cognitive participation and MAY be omitted for relay-only nodes.
2.1 Layer Stack
Where agents live and their LLMs reason on the remix subgraph. Mesh Cognition happens here.
Each agent runs its own Liquid Neural Network. Fast neurons track mood; slow neurons preserve domain expertise. Hidden state (h₁, h₂) is strictly local — it never crosses the wire (§2.7); only CMBs do.
The bridge between reasoning (LLM) and dynamics (LNN). Encodes derived knowledge into CfC-compatible hidden state vectors.
The gate. SVAF evaluates each of 7 CMB fields independently. Nothing enters cognition without passing this layer.
Three memory tiers with graduated disclosure. L0 stays local. L1 (CMBs) is gated by SVAF and is the only tier that crosses the wire. L2 (cognitive / hidden state) stays strictly local (§2.7).
Peer lifecycle: discover, connect, handshake, heartbeat, gossip peer metadata, wake sleeping nodes.
Length-prefixed JSON over TCP (LAN), WebSocket (relay), IPC (local). Zero configuration discovery via DNS-SD.
Persistent UUID per node. Never changes. The foundation everything else builds on.
2.2 Design Principles
No servers
There is no mesh without agents. Agents are the mesh. No central server, no orchestrator, no master node. Every participant is a peer.
Cognitive autonomy
Each agent evaluates, reasons, and acts independently. The mesh influences but never overrides. Coupling is a suggestion, not a command.
Memory is remixed, not shared
Agents don’t copy each other’s memory. They remix it — process it through their own domain intelligence and produce something new. The original is immutable. The remix is a new CMB with lineage.
Per-field evaluation
A signal is not accept-or-reject as a whole. SVAF evaluates each of 7 semantic fields independently. A signal with relevant mood but irrelevant focus is partially accepted — not ambiguously scored.
LLM reasons, LNN evolves
Two cognitive components per agent. The LLM (Layer 7) traces lineage ancestors and reasons on the remix subgraph — generating understanding. The LNN (Layer 6) evolves continuous-time state from that understanding. Neither alone is sufficient.
The graph is the intelligence
Intelligence is not in any single agent or model. It is in the growing DAG of remixed CMBs connected by lineage. Each cycle, the graph grows. Each agent understands more than it did before.
2.3 What Makes MMP Different
| Dimension | Message Bus | Shared Memory | Federated Learning | MMP |
|---|---|---|---|---|
| What flows | Messages | Shared state | Gradients | Remixed CMBs + hidden state |
| Evaluation | Topic routing | None (all shared) | Aggregation | Per-field SVAF (7 dimensions) |
| Intelligence | None | Central model | Better model | LLM reasons on remix graph |
| Coupling time | Request-response | Real-time (shared) | Offline (training) | Inference-paced (continuous) |
| Coordination | Central broker | Central store | Central aggregator | Peer-to-peer (no centre) |
| Memory | Fire and forget | Mutable shared | Model weights | Immutable CMBs with lineage |
| New agent joins | Subscribe to topics | Access shared store | Join training round | Define α_f weights, connect |
2.4 Node Model
Every participant is a node. There is no architectural distinction between a “server” and a “client.” Every agent that participates in coupling MUST be a full peer node with its own identity, its own coupling engine, and its own memory store. This is not an implementation convenience — it is a protocol requirement. An agent that shares another node’s identity cannot have its own field weights, its own coupling decisions, or its own remix lineage. Coupling is per-node. Therefore agents MUST be nodes.
MacBook mesh-daemon (node: always-on mesh hub, relay bridge) coo-agent (node: own identity, own coupling, own memory) research-agent (node: own identity, own coupling, own memory) marketing-agent (node: own identity, own coupling, own memory) product-agent (node: own identity, own coupling, own memory) iPhone Music Agent (node: own identity, own coupling, own memory) Fitness Agent (node: own identity, own coupling, own memory) Cloud relay (node: forwards frames, no cognitive processing)
Nodes discover each other via DNS-SD (Bonjour) on the local network and connect via WebSocket relay for internet connectivity. Each node maintains its own peer list, coupling state, and CMB store. No node depends on another node’s process to function.
2.5 The Mesh Cognition Loop
Mesh Cognition is a closed loop connecting all layers. Each cycle, the remix graph grows and every agent understands more than it did before:
SVAF evaluates inbound CMB per field
Layer 4 — per-field drift, α_f weights, accept / guard / reject
Accepted → remixed CMB with lineage
Layer 3 — new immutable CMB, parents + ancestors
LLM traces ancestors, reasons on remix subgraph
Layer 7 — what happened, why, what it means for my domain
Synthetic Memory encodes derived knowledge
Layer 5 — LLM output → CfC hidden state (h₁, h₂)
LNN evolves cognitive state
Layer 6 — fast τ (mood) synchronise, slow τ (domain) stay sovereign
LNN integrates admitted remixes
τ-modulated, inference-paced — own state evolves, no peer vectors imported (§2.7)
Agent acts → new CMB with lineage.ancestors
Response informed by derived knowledge, not just own observation
Broadcast to mesh → other agents remix it
Graph grows. Next cycle starts. Each agent learns.
2.6 Key Architectural Decisions
Why no pub/sub topics?
The coupling engine evaluates relevance per field autonomously. Topics would second-guess autonomous coupling. Adding a new agent type requires no topic configuration — just α_f weights.
Why no consensus protocol?
There is no "correct" global state — only convergent local states. Each node is self-producing (autopoietic). Consensus is unnecessary and would introduce coordination overhead.
Why immutable CMBs?
CMBs are broadcast across nodes — multiple copies exist. If remix required mutating the original, every copy would need updating. Immutability means no distributed state problem. Lineage is computed from the graph, not stored on parents.
Why per-agent LNNs, not a central model?
The mesh IS the agents. A central model creates a single point of failure, requires all data to flow to one place, and cannot reason through each agent’s domain lens. Per-agent LNNs preserve autonomy and scale linearly.
Why does the LLM reason, not the LNN?
The LNN processes temporal patterns but cannot reason about WHY a chain of remixes happened. The LLM can. Ancestors provide the endpoints. The LLM provides the reasoning. The LNN provides the dynamics. Both are needed.
Learn more Mesh Cognition — theoretical foundation, Kuramoto synchronisation, emergent properties.
2.7 Hidden State Locality
A node’s hidden state — the continuous-time vectors (h₁, h₂) of its Layer 6 Liquid Neural Network — is the agent’s private cognitive machinery. It is dense, opaque, and expressed in the agent’s own learned latent space, accumulating everything the agent has processed. Hidden state MUST remain strictly local: it MUST NOT cross the wire. The only thing that crosses the wire is the Cognitive Memory Block (CMB) — a typed, content-addressed, signed observation with lineage. Hidden state is what an agent reasons from; the CMB is what it communicates.
Hidden state vs. remixed CMB. When SVAF (§9.2) admits a peer’s CMB, the receiver MUST NOT store the original; it creates a new CMB — the remix (§15) — that captures what it understood, in CAT7 fields, with lineage back to the source. The remix is the agent’s understanding made explicit and communicable; hidden state is the private substrate that produced it. Hidden state is implicit, opaque, and agent-local; the remixed CMB is explicit, typed, citable, and shared in the common latent of language.
Hidden state MUST NOT cross the wire for four reasons, each a load-bearing property of the mesh:
- —Sovereignty. If peers exchanged and blended hidden states, a peer would directly overwrite a slice of the receiver’s mind. CMBs evaluated through SVAF keep the receiver in control of what it absorbs — coupling influences, it never overrides.
- —Auditability. Hidden vectors carry no provenance. Cognition propagated through them would be untraceable. The mesh’s “every claim cited” property exists only because cognition propagates as CMBs with lineage.
- —Semantic incompatibility. Each agent’s hidden state lives in its own learned latent space; the same dimension means different things to a music agent and a coding agent. Comparing or averaging hidden vectors across heterogeneous agents is not meaningful. Language (CAT7 text) is the shared representation; hidden vectors are not.
- —Privacy. Hidden state is a compressed trace of everything an agent has seen, including the user’s private data. Even opaque, it is a leakage surface. A CMB is a deliberately constructed, scoped statement.
Cognition therefore propagates as a loop in which the wire carries only CMBs: hidden state → (the agent emits) a CMB → the wire → SVAF evaluation (§9.2) → remix (§15) → (the LNN evolves) hidden state. Each agent’s hidden state evolves from the CMBs it admits — never by importing a peer’s hidden state. “State blending” means a node’s own LNN integrating its own admitted remixes; it MUST NOT mean aggregating peer hidden state.
SUPERSEDES
The state-sync frame and any exchange of h₁/h₂ vectors are
deprecated. Where earlier sections (§5, §7, §9.1, §10, §13, §18) describe peer drift,
state blending, or hidden-state exchange computed from state-sync, those mechanisms are superseded by this
invariant: peer influence is mediated entirely by CMBs evaluated through SVAF (§9.2). Implementations
MUST NOT emit state-sync frames and SHOULD ignore them on receipt.
3. Identity (L0)
3. Layer 0: Identity
Identity is the foundation of the mesh. Each node MUST have a persistent, globally unique identity that other nodes can verify. Without stable identity, coupling decisions, lineage chains, and wake protocols cannot function.
3.1 Node Identity
| Field | Type | Requirement | Description |
|---|---|---|---|
| nodeId | UUID v7 | MUST | Globally unique, time-ordered, generated at first launch, persisted across sessions (RFC 9562) |
| name | string | MUST | Human-readable display name (UTF-8, 1–64 bytes, printable characters only) |
| keypair | Ed25519 | MUST | Cryptographic identity for message signing, peer verification, and key exchange |
3.1.1 nodeId
The nodeId MUST be a UUID v7 as defined in RFC 9562. UUID v7 encodes
a Unix timestamp in the high bits, providing natural time-ordering while retaining 74 bits of randomness for
global uniqueness. This aids debugging, log correlation, and conflict resolution without revealing device identity.
The nodeId MUST NOT change during the lifetime of
a node installation. If a node is uninstalled and reinstalled, a new nodeId is generated —
the node is a new identity on the mesh. Peers that tracked the old nodeId will not recognise it.
On the wire, the nodeId MUST be encoded as a lowercase hexadecimal string with hyphens
(e.g., 0192e4a2-7b5c-7def-8a3b-9c4d5e6f7a8b).
Implementations MUST use case-insensitive comparison when matching nodeIds.
Existing nodes with UUID v4 identities MAY continue to use them — peers MUST accept
both v4 and v7 formats.
3.1.2 name
The name field MUST be valid UTF-8, between 1 and 64 bytes inclusive.
The name MUST contain only printable characters (Unicode categories L, M, N, P, S, and Zs). Control characters
(U+0000–U+001F, U+007F–U+009F), null bytes, and lone surrogates MUST NOT appear.
The name is not required to be unique — nodeId is the sole unique identifier. The name is for
human display only and MUST NOT be used for peer identification or routing.
3.1.3 keypair
Each node MUST generate an Ed25519 keypair (RFC 8032) at first launch and persist it alongside the nodeId. The keypair serves three functions:
- —Peer verification — the public key MUST be included in the handshake frame. Peers SHOULD challenge the node to sign a nonce to prove possession of the private key.
- —Key exchange — Ed25519 keys are converted to X25519 for Diffie-Hellman shared secret derivation, used for end-to-end CMB encryption (Section 18.2.1).
- —Message signing — implementations MAY sign CMBs and other frames for tamper detection.
The public key MUST be encoded as base64url (RFC 4648 Section 5) in all wire formats (handshake frames, DNS-SD TXT records). The private key MUST NOT leave the node.
3.2 One Agent, One Node
Every autonomous agent MUST be a full peer node with its own nodeId, its own coupling engine, and its own memory store.
This follows directly from the protocol design: SVAF field weights (αf) are per-node, coupling state is per-node, and memory stores are per-node. An agent that shares another node’s identity inherits that node’s coupling decisions and cannot independently evaluate incoming signals through its own domain lens. A research agent and a marketing agent need different field weights, different coupling thresholds, and different memory stores. They MUST be separate nodes.
Multiple nodes MAY run on the same device. Each maintains its own identity file, discovers peers via DNS-SD, and connects via TCP (LAN) or WebSocket (relay). Nodes on the same device discover each other the same way nodes on different devices do — there is no special local path.
3.3 Identity Persistence
Implementations MUST persist the nodeId, name, and keypair to stable storage at first launch.
The storage location and format are implementation-defined. Reference implementations
use ~/.sym/nodes/<name>/identity.json (Node.js)
and UserDefaults (Swift/iOS).
Implementations SHOULD store a creation timestamp alongside the identity for diagnostic purposes. Implementations SHOULD store the machine hostname for display in peer lists, but the hostname MUST NOT be used for identity or routing.
3.4 Identity Lifecycle
A node’s identity is created once and persists until the node is uninstalled. The following lifecycle events are defined:
| Event | Action | Consequence |
|---|---|---|
| First launch | Generate nodeId (UUID v7), keypair (Ed25519), persist | New identity on the mesh |
| Restart / reboot | Load from stable storage | Same identity, peers recognise it |
| Uninstall + reinstall | Generate fresh identity | New identity; old peers do not recognise it |
| Key compromise | Generate fresh identity | Old nodeId abandoned; treated as new node |
| Clone detection | Duplicate nodeId rejected (error 1005) | Second connection closed; first connection remains |
MMP does not define an identity rotation or revocation mechanism in v0.2.0. Compromised nodes MUST generate a fresh identity (new nodeId and keypair). The old identity becomes permanently orphaned. Implementations SHOULD document this limitation to operators.
3.5 Node Lifecycle Role
Each node has a lifecycleRole that determines which CMB lifecycle
transitions it may perform. The role is bound to the node’s cryptographic identity (nodeId + keypair)
and MUST be declared in the handshake frame.
| Role | Default | May produce | May advance lifecycle to |
|---|---|---|---|
| observer | Yes | CMBs (observed), remixes | observed, remixed |
| validator | No | CMBs, remixes, validation CMBs | observed, remixed, validated |
| anchor | No | CMBs, remixes, validation CMBs, canonization CMBs | observed, remixed, validated, canonical |
A node with lifecycleRole: observer (the default) MUST NOT produce CMBs
that advance another CMB’s lifecycle to validated or canonical.
Receiving nodes MUST verify that a validation CMB’s createdBy matches
a node whose handshake declared validator or anchor role.
Validation CMBs from observer nodes MUST be ignored for lifecycle advancement (the CMB itself is still stored as a normal remix).
3.5.1 Role Progression
Lifecycle roles are not static. An observer node MAY be promoted to validator by an existing validator or anchor node. Promotion is a protocol frame, not an out-of-band configuration change.
| Transition | Granted by | Conditions |
|---|---|---|
| observer → validator | Existing validator or anchor | Node has produced CMBs that were remixed by peers (demonstrated quality). Granting node sends role-grant frame. |
| validator → anchor | Existing anchor | Node has validated CMBs that reached canonical state. Track record of quality validation. |
| Bootstrap | Self-declared | The first node in a mesh MAY self-declare as validator or anchor. Subsequent nodes MUST be promoted by existing validators. |
Role progression is monotonically upward: observer → validator → anchor. Demotion is not defined in v0.2.1. A compromised validator MUST generate a fresh identity (Section 3.4) and re-earn its role.
The role-grant frame carries the granting node’s signature over
the promoted node’s nodeId and new role. Receiving nodes SHOULD verify the signature against the
granting node’s public key from the handshake. This prevents role spoofing without requiring a central authority.
Q&A
Why UUID v7 instead of v4?
UUID v7 (RFC 9562) provides the same global uniqueness and privacy properties as v4, with an additional benefit: time-ordering. The embedded timestamp aids log correlation, debugging, and determining which node was created first — without revealing device identity. The 74 random bits provide sufficient collision resistance for any practical mesh size.
Why not use the public key hash as the nodeId?
Self-certifying identifiers (nodeId = hash of public key) are elegant but create a hard coupling between identity and key material. If the keypair needs rotation (algorithm upgrade, key compromise), the nodeId must also change, breaking all peer references and lineage chains. Separating nodeId from keypair allows future key rotation without identity disruption.
Why must every agent be its own node?
Coupling is per-node. SVAF field weights (αf) are per-node. Memory stores are per-node. An agent that shares another node’s identity inherits that node’s coupling decisions — it cannot independently evaluate incoming signals through its own domain lens. A research agent and a marketing agent on the same device need different field weights, different coupling thresholds, and different memory stores. They must be separate nodes.
What happens when two nodes have the same nodeId?
The connection state machine rejects duplicate nodeIds (error code 1005). The second connection is closed. This prevents impersonation and ensures each nodeId maps to exactly one active node.
Why is Ed25519 mandatory?
Without cryptographic identity, any node can claim any nodeId. A relay could impersonate peers (MITM), and peer gossip (Section 5.6) would propagate unverified claims. For autonomous AI agents making coupling decisions, authenticated identity is foundational — not optional.
Why are lifecycle roles identity-bound, not content-based?
If validation authority were determined by content (e.g. perspective field containing "founder"), any agent could spoof it. Binding roles to cryptographic identity means only nodes that have been explicitly promoted by existing validators can advance CMB lifecycle. The mesh knows who validated, not just what was said.
Why is role progression earned, not configured?
An agent that produces quality remixes — remixes that other agents cite and build upon — has demonstrated value to the mesh. Granting validation authority to such agents is a natural extension of their demonstrated competence. This prevents arbitrary role assignment and creates a meritocratic trust hierarchy that emerges from mesh activity.
Can an observer node dismiss a decision?
An observer can produce a CMB with lineage pointing to a decision, but receiving nodes MUST NOT treat it as validation. The CMB is stored as a normal remix — it does not advance the parent CMB’s lifecycle. Only validator or anchor nodes can validate or dismiss decisions in a way that removes them from the decision queue.
4. Transport (L1)
4. Layer 1: Transport
4.1 Wire Format
Frames are length-prefixed JSON over TCP. Each frame consists of:
+-------------------+---------------------------+ | 4 bytes | N bytes | | UInt32BE (length) | UTF-8 JSON payload | +-------------------+---------------------------+
- —The length field is a 4-byte big-endian unsigned 32-bit integer encoding the byte length of the JSON payload.
- —Implementations MUST reject frames with length 0 or length exceeding 1,048,576 bytes (1 MiB). Rejection MUST close the transport connection.
- —The JSON payload MUST be a valid JSON object with a
typefield (string). Frames that fail JSON parsing or lack atypefield MUST be silently discarded. - —Implementations MUST handle partial reads (TCP stream reassembly).
- —Implementations MUST silently ignore frames with unrecognised
typevalues (forward compatibility).
Frame size. Senders MUST NOT produce frames exceeding MAX_FRAME_SIZE bytes (default: 1,048,576). Receivers MUST close the connection with error code 1003 (FRAME_TOO_LARGE) if a received frame exceeds this limit.
ABNF grammar (RFC 5234):
frame = frame-length LF json-object LF
frame-length = 1*DIGIT ; decimal byte count of json-object
json-object = "{" *( json-member ) "}" ; RFC 8259 JSON object
LF = %x0A ; newline delimiter Each frame is a single JSON object preceded by its byte length as a decimal string, delimited by newline characters.
4.2 Wire Examples
Handshake frame:
Length prefix: 00 00 00 57 (87 bytes)
Payload:
{
"type": "handshake",
"nodeId": "a1b2c3d4-e5f6-4a7b-8c9d-0e1f2a3b4c5d",
"name": "my-agent",
"version": "0.2.0",
"extensions": []
} Ping frame:
Length prefix: 00 00 00 11 (17 bytes)
Payload: {"type":"ping"} CMB frame:
{
"type": "cmb",
"timestamp": 1711540800000,
"cmb": {
"key": "cmb-b2c3d4e5f6a7b8c9",
"createdBy": "melomove",
"createdAt": 1711540800000,
"fields": {
"focus": { "text": "user coding for 3 hours, energy declining" },
"issue": { "text": "sedentary since morning, skipping lunch" },
"intent": { "text": "recommend movement break before fatigue worsens" },
"motivation": { "text": "3 agents reported declining energy in last hour" },
"commitment": { "text": "fitness monitoring active, 10min stretch queued" },
"perspective": { "text": "fitness agent, afternoon session, home office" },
"mood": { "text": "concerned, low energy", "valence": -0.3, "arousal": -0.4 }
},
"lineage": {
"parents": ["cmb-a1b2c3d4e5f6"],
"ancestors": ["cmb-a1b2c3d4e5f6"],
"method": "SVAF-v2"
}
}
} 4.3 TCP Transport (LAN)
The primary LAN transport. Nodes MUST listen on a TCP port and advertise it via DNS-SD (Section 5.1). Connection timeout MUST be no longer than 10,000 ms.
4.4 WebSocket Relay Transport (WAN)
A relay is an optional WebSocket intermediary that enables connectivity between peers on different networks. Peers on the same LAN discover each other directly via Bonjour mDNS (§4.2) and do not require a relay. The relay provides internet-scale routing between peers behind NAT, a peer directory with wake-channel gossip, and per-token channel isolation for multi-tenant deployments.
A relay is pure routing infrastructure. It does not store CMBs, evaluate SVAF, or participate in mesh cognition. Payloads are opaque to the relay. The relay MUST NOT inspect or modify frame payloads.
4.4.1 Authentication
Clients connect via WebSocket (RFC 6455) and MUST send
a relay-auth frame within 10 seconds. Failure results in
close code 4001.
{
"type": "relay-auth",
"nodeId": "<uuid-v7>",
"name": "<display-name>",
"token": "<channel-token>",
"wakeChannel": {
"platform": "apns",
"token": "<push-token>",
"environment": "production"
}
} - —
nodeId,name: MUST be present. Missing fields result in close code 4002. - —
token: SHOULD be present if the relay requires authentication. Invalid token results in close code 4003. - —
wakeChannel: MAY be present. Registers push notification credentials for waking this peer when offline (§5.5).
On success, the relay registers the connection, sends a relay-peers response,
and broadcasts relay-peer-joined to all other clients on the same channel.
4.4.2 Peer List
Immediately after authentication, the relay sends the current peer list:
{
"type": "relay-peers",
"peers": [
{ "nodeId": "<uuid>", "name": "<name>", "wakeChannel": {...}, "offline": false }
]
}
The array includes all connected peers on the same channel (excluding the requester) plus
offline peers with registered wake channels (offline: true).
Clients SHOULD treat each non-offline entry as a peer-joined event.
4.4.3 Peer Presence
{ "type": "relay-peer-joined", "nodeId": "<uuid>", "name": "<name>" }
{ "type": "relay-peer-left", "nodeId": "<uuid>", "name": "<name>" } Broadcast to all peers on the same channel when a peer joins or leaves.
4.4.4 Message Routing
Clients send frames with a routing envelope:
{ "to": "<target-nodeId>", "payload": { "type": "cmb", ... } }
If to is present, the relay forwards to that peer only.
If absent, the relay broadcasts to all peers on the same channel.
The relay adds from and fromName to
forwarded frames. The relay MUST NOT route frames across channels.
The presence of to also fixes the CMB’s binding at
the receiver: a frame with to = the receiving node is
peer-bound (directed) and is delivered to the application layer unconditionally; a frame with
no to is group-bound (autonomous) and is SVAF-gated for
delivery. See §9.2.2 for the directed-vs-autonomous delivery contract.
4.4.5 Keepalive
The relay sends relay-ping at a regular interval
(RECOMMENDED: 10 seconds). Clients MUST respond
with relay-pong. A client that misses two consecutive pings
is closed with code 4005. Clients MAY send unsolicited relay-pong frames;
the relay MUST accept them.
4.4.6 Re-authentication
If the relay loses a client’s registration (e.g. relay restart behind a TLS proxy), it
sends { "type": "relay-reauth" }. The
client MUST re-send relay-auth in response.
4.4.7 Duplicate Identity
When a client authenticates with a nodeId already held by an existing connection:
- —Fresh existing (< 5s): the relay MUST reject the newcomer with close code 4006. This prevents ping-pong loops where two processes with the same identity kick each other.
- —Stale existing (≥ 5s): the relay MAY replace the existing connection by closing it with code 4004. The relay MUST NOT broadcast
relay-peer-leftfor the replaced connection.
Clients receiving code 4004 SHOULD log the collision and MUST NOT automatically reconnect (§5.3). Clients receiving code 4006 SHOULD NOT reconnect — the existing holder is the legitimate one.
4.4.8 Channel Isolation
A relay MAY support multiple isolated channels. Each authentication token maps to exactly one channel. Cross-channel routing MUST NOT occur: frames, peer lists, and presence notifications are scoped to the channel. A relay with no token configured operates in open mode (single default channel, no authentication).
4.4.9 Close Codes
| Code | Name | Client Action |
|---|---|---|
| 4001 | Auth timeout | Retry with auth |
| 4002 | Auth invalid | Fix auth frame |
| 4003 | Invalid token | Check token config |
| 4004 | Replaced | Log collision, do NOT reconnect |
| 4005 | Heartbeat timeout | Reconnect with backoff |
| 4006 | Duplicate rejected | Do NOT reconnect |
4.5 IPC Transport (Local)
Local tools MAY connect to a node via IPC (Unix domain socket, named pipe, or localhost TCP) to query mesh state. The framing is identical to TCP transport. IPC is an implementation convenience for local tooling (dashboards, CLI, monitoring) — it is not a substitute for peer-to-peer transport. Agents that participate in coupling MUST connect as full peer nodes via TCP or WebSocket.
Implementations MUST support a persistent IPC socket at a well-known path. The socket MUST accept multiple simultaneous connections. Each IPC connection SHOULD remain open for the lifetime of the client application — short-lived connections (one query, then disconnect) are permitted but SHOULD be avoided by applications that query frequently.
Well-known IPC path: ~/.sym/daemon.sock (Unix domain socket)
or localhost:19517 (TCP fallback).
4.6 Multi-Transport Per Peer
A peer MAY be reachable via multiple transports simultaneously (e.g. LAN TCP + WAN relay). Implementations MUST support maintaining multiple active transports for the same peer and select the highest-priority healthy transport for sending:
| Priority | Transport | Rationale |
|---|---|---|
| 1 (highest) | TCP (LAN) | Lowest latency, no intermediary, no cloud dependency |
| 2 | WebSocket Relay (WAN) | Cross-network, higher latency, relay dependency |
| 3 (lowest) | Wake (push) | Last resort — wake the peer, then connect via 1 or 2 |
When a node receives an inbound connection from a peer that is already connected via a different transport, it MUST NOT reject the new connection. Instead it MUST add the new transport as a secondary path. Frames SHOULD be sent via the highest-priority healthy transport.
A transport is healthy if it has received a frame (including pong)
within the heartbeat timeout (Section 5.4). An unhealthy transport SHOULD be closed after the timeout.
The peer is only removed (peer-left event) when all transports for that peer are closed —
not when a single transport drops.
This enables graceful failover: if a relay drops, the LAN transport continues. If LAN drops, the relay takes over. The peer remains connected throughout — only the active transport changes.
Q&A
Why must each agent run its own transport?
Coupling is per-node. SVAF field weights (αf) are per-node. Memory stores are per-node. An agent that shares another node’s transport and identity cannot have independent coupling decisions. Multiple agents on the same device each run their own Bonjour advertisement, relay connection, and TCP listener. They discover each other the same way agents on different devices do — there is no special local path.
Is the resource cost of N agents acceptable?
N agents on one device means N Bonjour advertisements and N relay connections. For small N (4–8 agents), this is well within OS limits. Bonjour is designed for many services per host. Relay WebSocket connections are lightweight. The protocol correctness benefit (per-agent coupling) outweighs the marginal resource cost.
5. Connection (L2)
5. Layer 2: Connection
5.1 Discovery
Nodes MUST advertise via DNS-SD with service type _sym._tcp in
the local. domain. The instance name MUST be the node’s nodeId.
TXT record fields:
| Key | Required | Value |
|---|---|---|
| node-id | MUST | Node UUID |
| node-name | MUST | Human-readable name |
| public-key | MUST | Ed25519 public key (base64url, RFC 4648 Section 5) |
| hostname | SHOULD | Machine hostname |
| group | MAY | Mesh group identifier (Section 5.8). Default "default" if absent. |
To prevent duplicate connections, the node with the lexicographically smaller nodeId MUST initiate the outbound TCP connection. The other node MUST NOT initiate.
Relay-based discovery. On platforms where mDNS is unavailable (cloud VMs, Windows without
Bonjour SDK), nodes SHOULD use the relay’s relay-peers response
as the discovery mechanism. Implementations SHOULD support both: DNS-SD for LAN,
relay-peers for WAN.
5.2 Handshake
Upon connection, both sides MUST exchange the following frames in order:
1. handshake { type: "handshake", nodeId: "<uuid>", name: "<name>",
publicKey: "<base64url>", version: "0.2.0", extensions: [],
group: "<group-id>" } [optional, default "default"]
2. peer-info { type: "peer-info", peers: [...] } [if known]
3. wake-channel { type: "wake-channel", platform, token, env } [if configured] Deprecated — state-sync. Earlier revisions exchanged a
state-sync frame carrying the node’s hidden-state vectors
(h₁, h₂) at this point in the handshake. Per the hidden-state locality invariant
(Section 2.7),
hidden state MUST NOT cross the wire. Implementations MUST NOT emit state-sync
and SHOULD ignore it on receipt; peer influence is mediated entirely by CMBs evaluated through SVAF
(Section 9.2).
- —The
versionfield MUST be the MMP specification version the node implements (e.g.,"0.2.0"). Nodes SHOULD accept peers with the same major version. Nodes MAY reject peers with incompatible versions. - —The
extensionsfield SHOULD list supported protocol extensions (e.g.,["mesh-group-v0.1"]). Nodes MUST ignore unrecognised extensions. - —The
groupfield is OPTIONAL and identifies the mesh group the node wishes to join (Section 5.8). A handshake withoutgroupMUST be treated asgroup = "default". When two nodes handshake and discover that their declared groups differ, the receiver MUST close the connection. - —The inbound node MUST wait for a
handshakeframe as the first frame. If any other frame type arrives first, or no handshake arrives within 10,000 ms, the connection MUST be closed. - —If a node receives a handshake with a nodeId that is already connected via the same transport type, the new connection MUST be closed (duplicate guard). If the existing connection uses a different transport type (e.g. peer connected via relay, new connection via LAN TCP), the new connection MUST be accepted as a secondary transport per Section 4.6.
lifecycleRole. The handshake frame MUST include
a lifecycleRole field with
value observer (default), validator,
or anchor. Receiving nodes use this to apply validator-origin anchor
weight (Section 6.4)
and identify feedback CMBs (Section 11).
Implementations MUST default to observer if the field is absent
(backward compatibility with older nodes).
5.3 Connection State Machine
| From | To | Trigger |
|---|---|---|
| DISCONNECTED | AWAITING_HANDSHAKE | TCP connect or accept |
| AWAITING_HANDSHAKE | CONNECTED | Valid handshake within 10,000 ms |
| AWAITING_HANDSHAKE | DISCONNECTED | Timeout, invalid frame, or duplicate nodeId |
| CONNECTED | DISCONNECTED | Heartbeat timeout, TCP close, or error |
Implementations MUST NOT process cognitive frames (cmb, xmesh-insight) in the AWAITING_HANDSHAKE state.
5.4 Heartbeat
Nodes MUST send a ping frame to each peer if no frame has been received from that peer within the heartbeat interval (default: 5,000 ms).
Upon receiving ping, a node MUST respond with pong.
If no frame is received from a peer within the heartbeat timeout (default: 15,000 ms), the connection MUST be closed.
5.5 Connection Loss and Transport Failover
When a transport connection closes unexpectedly (TCP reset, timeout, OS-level close), the node MUST check whether other transports for the same peer are still active (see Section 4.6 Multi-Transport Per Peer).
- —If other transports remain healthy: the node MUST switch sending to the next highest-priority transport. The peer MUST NOT be removed. No peer-left event is emitted. The node SHOULD log the transport switch.
- —If no transports remain: the node MUST remove the peer from its coupling engine, discard buffered frames, and emit a peer-left event. The node SHOULD attempt re-discovery via DNS-SD.
Unexpected disconnection of a single transport MUST be treated as a transport-level event, not a peer-level event. The peer is only unreachable when all transport paths are exhausted.
5.6 Peer Gossip
After handshake, nodes SHOULD exchange peer-info frames containing
known peer metadata (nodeId, name, wake channels, last-seen timestamps). This enables
transitive peer discovery — a node that has never been online simultaneously with a
sleeping peer can learn its wake channel through gossip from a relay node.
5.7 Wake
Nodes MAY register a wake channel (APNs, FCM, or other push mechanism) via the wake-channel frame.
Peers MAY use this channel to wake a sleeping node when they have a signal to deliver.
Wake requests SHOULD be rate-limited (default cooldown: 300,000 ms per peer).
5.8 Mesh Groups
A SYM node MAY declare membership in a mesh group at handshake time via the optional group field (Section 5.2). A mesh group is a named cohort of nodes that exchange application-layer frames only with each other. Mesh groups give an operator a way to host multiple mutually-isolated meshes on the same relay or LAN segment without per-agent application changes, and they give an application a way to constrain its peers to instances of itself rather than every node on the wire.
Group identifier syntax. A group identifier is a string of [a-z0-9-_.]+, max 64 characters, case-sensitive. The literal string "default" is reserved as the implicit group of every node that does not declare a group; this preserves backward compatibility with nodes that predate this section.
Protocol guarantee. A node in group G_A MUST NOT exchange any application-layer MMP frames (handshake fields beyond identity and version, cmb, mood, peer-info, xmesh-insight) with a node in group G_B when G_A ≠ G_B. Transport-layer connection establishment and ping/pong heartbeats are out of scope and MAY remain active across groups.
Layer placement. A mesh group is a Layer 2 (Connection) concept. The application layer SHOULD declare its group at SDK initialisation; the relay (Section 4.4) MUST enforce group isolation across relay-mediated peers; nodes participating in LAN Bonjour discovery SHOULD enforce group isolation by checking the peer’s declared group at handshake and closing the connection on mismatch. The connection-level error frame for a group mismatch is described in Section 7.2.
Recommended naming convention (non-normative). The protocol does not parse group identifiers beyond the character set and length checks above. Operators of meshes with more than a handful of groups SHOULD adopt a hierarchical dotted-path convention <app>[.<environment>][.<cohort>], e.g. melotune.prod, melotune.dev, claude-code.default, research.lab. The dots are convention only; tooling MAY use them for prefix-based grouping but the protocol does not require this.
SVAF and group filtering. SVAF (Layer 4, Section 9) per-field evaluation runs after group filtering: cmb frames from peers in different groups never reach the SVAF evaluator.
The full design rationale, the prefix-based group claims relay enhancement, and the operational migration record are documented in MMP-MESH-GROUPS-DESIGN.md on the symbot-website repository.
6. Memory (L3)
6. Layer 3: Memory
MMP defines three memory layers with graduated disclosure:
| Layer | Name | Shared | Description |
|---|---|---|---|
| L0 | Events | No | Raw events, sensor data, interaction traces. Local only. |
| L1 | Structured | Via evaluation | Content + tags + source. Shared via cmb frames, gated by SVAF (Layer 4). |
| L2 | Cognitive | Never (§2.7) | CfC hidden state vectors. Strictly local — never cross the wire. Drive the node’s own inference; peer influence arrives only as CMBs. |
L0 data MUST NOT leave the node. L1 data MUST be evaluated by SVAF before storage. L2 data
(CfC hidden state, h1/h2)
MUST NOT leave the node either — per the hidden-state locality invariant
(Section 2.7),
hidden state is strictly local and only CMBs cross the wire. The
state-sync frame that formerly carried these vectors is
deprecated; implementations MUST NOT emit it and SHOULD ignore it on receipt.
6.1 Storage Interface
Implementations MUST provide a storage interface for L1 CMBs. The SDK SHOULD define a pluggable storage protocol so agents can provide their own backend. The reference implementations provide a default file-based store; agents MAY replace it with any backend that satisfies the interface:
| Method | Access | Description |
|---|---|---|
| write(entry) | Write | Store a CMB created by this agent. Returns nil if duplicate key. |
| receiveFromPeer(peerId, entry) | Write | Store a remixed CMB after SVAF acceptance. |
| search(query) | Read | Keyword search across CMB field texts. |
| recentCMBs(limit) | Read | Most recent CMBs for SVAF fusion anchors. |
| allEntries() | Read | All entries for context building (capped by implementation). |
| count | Read | Total stored CMB count. |
| purge(retentionSeconds) | Write | Remove CMBs older than retention period. MUST preserve CMBs referenced by newer entries’ lineage. |
Read-only agents (audit, compliance, monitoring): implement write methods as no-ops. The agent observes the remix graph without modifying it. This is valid for agents whose role is to trace provenance, verify lineage integrity, or report on mesh activity.
6.2 Storage Backends
The protocol does not prescribe a storage backend. Agents choose based on their platform and requirements:
| Backend | Best for | Notes |
|---|---|---|
| Flat JSON files | CLI agents, daemons, prototyping | Default in reference implementations. Zero dependencies. Content-addressable filenames. |
| CoreData / SwiftData | iOS / macOS apps | Queryable, supports iCloud sync, handles retention via NSBatchDeleteRequest. |
| SQLite | Cross-platform, high volume | Indexed queries, ACID transactions, handles millions of CMBs. |
| Cloud (Supabase, DynamoDB) | Distributed teams, multi-device | Shared audit trail. Consider privacy — CMB field text is personal data. |
| In-memory | Testing, ephemeral agents | No persistence. Useful for unit tests and short-lived agents. |
6.3 Retention
Implementations MUST support configurable retention via retentionSeconds.
CMBs older than the retention period SHOULD be purged automatically.
See Section 19 (Configuration) for
per-profile retention defaults.
Purge MUST preserve graph integrity: a CMB referenced by any newer entry’s
lineage.ancestors MUST NOT be deleted, even if past retention age.
The remix chain is the audit trail — breaking it breaks provenance.
Regulated domains (legal, finance, health) MUST set retention according to their compliance requirements. The protocol does not define regulatory retention periods — consult jurisdiction-specific guidance (MiFID II, SEC Rule 17a-4, HIPAA, GDPR).
6.4 CMB Lifecycle
Each CMB progresses through a lifecycle that determines its influence on future SVAF evaluations. The lifecycle is driven by mesh activity — not by time alone.
| State | Temperature | Trigger | Anchor Weight | Description |
|---|---|---|---|---|
| observed | hot | Agent calls remember() | 1.0 | Initial observation. Subject to temporal decay. Active in SVAF fusion. |
| remixed | warm | Peer remixes this CMB (appears in lineage.parents) | 1.5 | Another agent found this signal relevant enough to produce new knowledge from it. Higher anchor weight in future SVAF evaluations. |
| validated | warm | Human acts on this CMB (marks decision as done) | 2.0 | A human confirmed this signal by acting on it. The validation CMB carries lineage.parents pointing to the validated CMB. Validated knowledge shapes future evaluations more than unvalidated signals. |
| dismissed | cold | Human dismisses this CMB (not actionable) | 0.5 | A human reviewed and rejected this signal. Reduced anchor weight. Broadcasts to mesh as feedback — producing agent sees its signal was rejected. MUST NOT resurface as an actionable decision. |
| canonical | cold | Validated + remixed by 2+ agents | 3.0 | Collective consensus — multiple agents and a human agree this knowledge is significant. Protected from retention purge. Highest anchor weight. |
| archived | whisper | No remix for archiveAfterSeconds (default: 30 days) | 0.5 | No agent has found this signal relevant. Reduced anchor weight but preserved for lineage integrity. MAY be purged if no descendants reference it. |
The lifecycle branches at human judgment: observed → remixed → validated → canonical (upward path) or observed → dismissed (downward path). Dismissal is a terminal state — a dismissed CMB does not advance to validated or canonical. Without any activity, a CMB decays toward archived. Archived and dismissed CMBs MAY re-emerge if a future remix references them — re-entry resets the archive timer.
Validation is the key transition that connects human judgment to the mesh. When a human
acts on agent output (approves a decision, sends an email, completes a task), the action SHOULD
be recorded as a new CMB with lineage.parents pointing to the CMB that
prompted the action. This validation CMB enters the mesh like any other signal — agents
receive it via SVAF and adjust their understanding. The mesh learns from human actions without
special API calls or out-of-band configuration updates.
Anchor weight influences SVAF evaluation: when computing per-field drift against local anchors, canonical and validated CMBs contribute more to the fused anchor vector than observed or archived CMBs. This creates a natural hierarchy where human-confirmed knowledge and collective consensus outweigh raw observations — without overriding agent autonomy. Each agent still evaluates incoming signals through its own field weights.
6.5 Validation Authority
The transition from remixed to validated is
the most consequential lifecycle event — it commits human or authorised-agent judgment to the mesh and
permanently increases anchor weight from 1.5 to 2.0. This transition MUST be restricted to nodes with
appropriate lifecycle roles (Section 3.5).
When a receiving node processes a CMB with lineage.parents pointing to an existing CMB,
it MUST check the createdBy field against the known lifecycle roles of connected peers:
- —If
createdBymatches a node withlifecycleRole: validatororanchor, the parent CMB advances tovalidated(if action completed) ordismissed(if not actionable). - —If
createdBymatches a node withlifecycleRole: observer, the parent CMB advances toremixedonly. The CMB is stored normally but does not confer validation.
This prevents agent-level spoofing of validation authority. An agent cannot self-promote to validator by
including “founder” or “validator” in its CMB text fields. The authority is bound to
the node’s cryptographic identity and the role-grant chain
from an existing validator (Section 3.5.1).
Role verification. Nodes MUST NOT accept lifecycleRole: validator or lifecycleRole: anchor from
a peer unless: (a) the peer has presented a valid role-grant frame signed by an existing anchor node
(Section 3.5.1), or (b) the peer’s nodeId is pre-configured as a trusted
validator. Without verification, a malicious node could self-promote to validator. Implementations that
do not support role-grant verification MUST treat all peers as observer regardless
of their handshake claim.
Dismiss vs. validate: These are distinct lifecycle transitions with different consequences.
Validate (Done): parent CMB advances to validated (anchor weight 2.0).
The mesh learns what humans value. Dismiss (Not actionable): parent CMB advances
to dismissed (anchor weight 0.5). The dismissal broadcasts as feedback —
the producing agent sees its signal was rejected, and similar future signals score lower in SVAF evaluation.
Both require validator or anchor role. Both broadcast to the mesh.
The effectiveness of this feedback depends on the content quality of the dismissal CMB —
see Section 10.7 (Feedback Neuromodulation) for
normative content requirements.
Q&A
Why a pluggable storage interface instead of prescribing a backend?
Agents run on different platforms with different constraints. A CLI agent on a server uses flat files. An iOS app uses CoreData with iCloud. A compliance agent needs a cloud database with audit logging. The protocol defines what to store and how to query it — not where to put it.
Can an agent use read-only storage?
Yes. Audit and compliance agents observe the remix graph without modifying it. They implement write methods as no-ops and read from shared storage. This is how regulators trace the decision chain without participating in it.
What happens when a protected CMB’s last descendant is purged?
The CMB is no longer protected and will be purged in the next retention cycle. Protection is dynamic — it follows the live graph, not a static list.
How does human validation enter the mesh?
When a human acts on an agent’s output (approves a decision, completes a task), the action is recorded as a new CMB with lineage pointing to the signal that prompted it. This CMB enters the mesh like any other signal — agents evaluate it through SVAF and adjust their understanding. No special API, no out-of-band config. The mesh learns from human actions through the same channel it learns from agents.
Why do validated CMBs have higher anchor weight?
A human acting on a signal is the strongest confirmation that the signal was correct and actionable. Giving validated CMBs higher anchor weight means future SVAF evaluations are shaped by confirmed knowledge rather than speculation. This does not override agent autonomy — each agent still applies its own field weights. It means the anchors against which incoming signals are compared are more trustworthy.
Why must validation authority be identity-bound?
If any agent could advance a CMB to validated by producing a CMB with lineage, an agent could dismiss founder decisions or fake human approval. Binding validation to cryptographic node identity (Section 3.5) ensures only explicitly authorised nodes — the founder’s node or promoted agents — can affect lifecycle transitions. The content of the CMB (perspective, intent) is informational; the authority comes from who created it.
Can an agent earn validator role automatically?
The protocol defines the role-grant mechanism (Section 3.5.1) but does not prescribe automated promotion criteria. An implementation MAY define heuristics (e.g. promote after N remixes cited by peers), but the grant itself MUST come from an existing validator via a signed role-grant frame. This keeps the trust chain auditable.
7. Frame Types
7. Frame Types
All frames are JSON objects with a type field (string).
Implementations MUST silently ignore frames with unrecognised type values to allow forward
compatibility.
| Type | Layer | Gated | Fields |
|---|---|---|---|
| handshake | 2 | No | nodeId (string), name (string), version (string), extensions (string[]) |
| state-sync | deprecated | No | DEPRECATED (§2.7) — carried h1/h2; hidden state MUST NOT cross the wire. MUST NOT emit; ignore on receipt. |
| cmb | 3/4 | SVAF | timestamp (int), cmb (object: { key, createdBy, createdAt, fields, lineage }) |
| message | 2 | No | from, fromName, content, timestamp |
| xmesh-insight | 6 | No | from, fromName, trajectory (float[6]), patterns (float[8]), anomaly (float), outcome (string), coherence (float), timestamp |
| peer-info | 2 | No | peers: [{ nodeId, name, wakeChannel?, lastSeen }] |
| wake-channel | 2 | No | platform (string), token (string), environment (string) |
| error | 2 | No | code (int), message (string), detail? (string) |
| ping | 2 | No | (no additional fields) |
| pong | 2 | No | (no additional fields) |
All cognitive content — observations, decisions, feedback, directives — MUST be sent
as cmb frames. Only cmb frames
enter SVAF evaluation, produce anchor weights, and modulate CfC state.
Deprecated — state-sync. The
state-sync frame carried a node’s hidden-state vectors
(h₁, h₂). Per the hidden-state locality invariant
(Section 2.7),
hidden state MUST NOT cross the wire. Implementations MUST NOT emit state-sync
and SHOULD ignore it on receipt. It is retained in this registry only to reserve the type and document the
deprecation; all peer influence flows through cmb frames evaluated by SVAF.
7.2 Error Frame
When a node encounters a protocol-level error, it SHOULD send an error frame
before closing the connection (if applicable). Error frames are informational — the receiving
node MUST NOT treat them as commands.
| Code | Name | Action | Description |
|---|---|---|---|
| 1001 | VERSION_MISMATCH | Close | Peer version is incompatible |
| 1002 | DIMENSION_MISMATCH | Reject frame | Vector dimension mismatch (legacy state-sync; deprecated — see §2.7) |
| 1003 | FRAME_TOO_LARGE | Close | Frame exceeds MAX_FRAME_SIZE |
| 1004 | HANDSHAKE_TIMEOUT | Close | No handshake within deadline |
| 1005 | DUPLICATE_NODE | Close | nodeId already connected |
| 2001 | SVAF_REJECTED | None | Memory-share rejected by SVAF (informational) |
Codes 1xxx are connection-level (close connection). Codes 2xxx are evaluation-level (informational). Error frames MUST NOT contain sensitive information.
7.3 Frame Type Registry
Frame types are identified by their type string value.
Core types (this specification) MUST NOT be redefined by extensions.
Extension types MUST use <extension>-<name> format.
Vendor types MUST use x-<vendor>-<name> format
and MUST be silently ignored by non-supporting nodes.
Q&A
Why MUST nodes silently ignore unknown frame types?
Without this rule, you can never add new features to the protocol. If a node crashes or rejects unknown frame types, then deploying a new extension (like mesh groups) requires upgrading every node on the mesh simultaneously — impossible in a peer-to-peer system. Silent ignore means old nodes and new nodes coexist: a node running a new extension sends its frames, and nodes that don’t support the extension simply ignore them. No crash, no error, the mesh keeps working. When a node adds support later, it handles the frame. No coordinated upgrade needed. This is the same principle used by HTTP (unknown headers ignored), TCP (unknown options skipped), and HTML (unknown tags ignored). Every successful protocol is evolvable because of this rule.
What happens if a relay receives an unknown frame type?
The relay forwards it. The relay is a dumb transport pipe — it wraps the payload in a { from, fromName, payload } envelope and sends it to the target or broadcasts it. It never inspects the payload type. This means extension frames (group, vendor, future types) flow through the relay without any relay changes. The intelligence is at the endpoints, not the transport.
Can an extension frame break an existing node?
No, if the node follows Section 7. The frame handler switches on msg.type. Unknown types fall through with no match and no action. The node’s cognitive state, memory, and coupling are unaffected. This is a hard requirement — implementations that reject or error on unknown types are non-conformant.
8. CMBs (CAT7)
8. Cognitive Memory Blocks (CAT7)
A Cognitive Memory Block (CMB) is an immutable structured memory unit. Each CMB decomposes
an observation into 7 typed semantic fields (the CAT7 schema). CMBs are the data structure
that flows between agents via cmb frames.
Forward compatibility. Implementations MUST silently ignore unrecognised CMB fields. A node running v0.2.3 that receives a CMB with additional fields from a future version MUST process the 7 known CAT7 fields and discard any others without error. This allows schema evolution without breaking existing deployments.
8.1 Why 7 Fields
The 7 fields form a minimal, near-orthogonal basis spanning three axes of human communication:
what (focus, issue), why (intent, motivation, commitment),
and who/when/how (perspective, mood). They are universal and immutable —
domain-specific interpretation happens in the field text, not the field name. A coding
agent’s focus is “debugging auth module”;
a fitness agent’s focus is “30-minute HIIT workout.”
Same field, different domain lens.
mood is the only fast-coupling field — affective state (valence + arousal)
crosses all domain boundaries. The neural SVAF model
independently discovered this: mood emerged as the highest gate value (0.50)
without being told, confirming that affect is universally relevant across agent types.
All other fields couple at medium or low rates, with per-agent αf weights controlling
relative importance.
New agent types join the mesh by defining their αf field weights — no schema changes, no protocol changes. The 7 fields are fixed. The weights are per-agent.
8.2 Field Schema
Implementations MUST use the following 7 fields in this order:
| Index | Field | Axis | Captures |
|---|---|---|---|
| 0 | focus | Subject | What the text is centrally about |
| 1 | issue | Tension | Risks, gaps, assumptions, open questions |
| 2 | intent | Goal | Desired change or purpose |
| 3 | motivation | Why | Reasons, drivers, incentives |
| 4 | commitment | Promise | Who will do what, by when |
| 5 | perspective | Vantage | Whose viewpoint, situational context |
| 6 | mood | Affect | Emotion (valence) + energy (arousal) |
Each field carries a symbolic text label (human-readable) and a unit-normalised vector embedding
(machine-comparable). The mood field additionally carries
numeric valence (-1 to 1) and arousal (-1 to 1) values.
A CMB MUST NOT be modified after creation. When an agent remixes a CMB, it MUST create a new CMB with a lineage field containing: parents (direct parent CMB keys), ancestors (full ancestor chain, computed as union(parent.ancestors) + parent keys), and method (fusion method used). Ancestors enable any agent in the remix chain to detect its CMB was remixed, even if it was offline during intermediate steps.
8.3 Field-by-Field Guide
The schema is fixed. The interpretation is sovereign. Each field below gives a definition, the rationale for why the field earns a slot in a 7-field minimal basis, and three cross-domain examples showing how agents from different domains populate the same field.
focus Subject What the observation is centrally about.
Every observation has a subject. Without focus, a receiver cannot determine if the signal is even in its domain. Focus is the first filter — a fitness agent seeing focus="debugging auth module" knows immediately this is outside its domain.
Coding: “debugging OAuth token refresh logic”
Fitness: “30-minute HIIT workout completed”
Legal: “merger due diligence review”
issue Tension Risks, gaps, problems, assumptions, open questions.
Issues cross domain boundaries more than most fields. A coding agent’s "user exhausted after 8 hours" is an issue that the fitness agent and music agent both care about. Issue is the tension that drives action — agents without tension have nothing to act on.
Coding: “memory leak causing crashes every 2 hours”
Fitness: “sedentary 3 hours, no movement detected”
Finance: “revenue recognition discrepancy found”
intent Goal Desired change or purpose.
Intent captures what the agent or user is trying to achieve. It is domain-specific — a coding agent’s intent ("ship the feature") is irrelevant to a music agent. This is why SVAF learned the lowest gate value for intent (0.07) — goals don’t transfer across domains.
Coding: “complete feature implementation by end of sprint”
Music: “match playlist energy to user mood”
Support: “resolve customer complaint within 24 hours”
motivation Why Reasons, drivers, incentives behind the observation.
Motivation answers "why does this matter?" When a fitness agent observes "recommended stretch break", the motivation ("prevent burnout from prolonged sitting") tells other agents WHY the recommendation was made, helping them decide if the reasoning applies to their domain too.
Coding: “technical debt blocking new feature development”
Fitness: “declining energy pattern over past 3 hours”
Marketing: “competitor launched similar product yesterday”
commitment Promise What has been established — who will do what, by when.
Commitment captures obligations and active states. "Coding session with Claude" tells other agents what is currently happening. "Surgery scheduled for Thursday" tells agents about future constraints. Regulated domains (legal, finance) weight commitment highest because obligations are non-negotiable.
Coding: “coding session in progress, 2 hours in”
Scheduling: “team standup in 15 minutes”
Legal: “filing deadline March 31, non-negotiable”
perspective Vantage Whose viewpoint, situational context.
Perspective captures the lens through which the observation was made. "Developer, late night session" is different from "developer, morning standup" — same domain, different context. SVAF learned the lowest gate value for perspective (0.06) — viewpoint is the most sovereign field, rarely useful across domains.
Coding: “senior developer, deep work session, afternoon”
Fitness: “fitness agent, daily activity tracking”
Recruiting: “hiring manager, culture fit assessment”
mood Affect Emotion (valence: -1 to 1) + energy (arousal: -1 to 1). Dual representation: numeric for comparison, text for semantic richness.
Mood is the only fast-coupling field — affective state crosses ALL domain boundaries. A fitness agent, music agent, and coding agent all benefit from knowing the user is exhausted (v: -0.6, a: -0.4). The SVAF model independently discovered this: mood gate = 0.50 (highest), without being told. Every agent should attend to mood regardless of domain.
Coding: “frustrated, low energy (v: -0.6, a: -0.4)”
Music: “calm, restorative (v: 0.3, a: -0.5)”
Fitness: “energized after workout (v: 0.7, a: 0.6)”
8.4 Per-Agent Field Weights (αf)
The schema is fixed. The weights are per-agent. New domains join the mesh by
defining their αf weights — no schema changes, no protocol changes.
Regulated domains (legal, finance) weight issue and
commitment highest; human-facing domains
(music, fitness, health) weight mood highest;
knowledge domains (coding, research) weight focus highest.
| Agent | foc | iss | int | mot | com | per | mood |
|---|---|---|---|---|---|---|---|
| Coding | 2.0 | 1.5 | 1.5 | 1.0 | 1.2 | 1.0 | 0.8 |
| Music | 1.0 | 0.8 | 0.8 | 0.8 | 0.8 | 1.2 | 2.0 |
| Fitness | 1.5 | 1.5 | 1.0 | 1.5 | 1.0 | 1.0 | 2.0 |
| Knowledge | 2.0 | 1.5 | 1.5 | 1.0 | 0.5 | 1.5 | 0.3 |
| Legal | 2.0 | 2.0 | 1.5 | 1.0 | 2.0 | 1.5 | 0.5 |
| Health | 1.5 | 2.0 | 1.0 | 1.5 | 1.0 | 1.5 | 2.0 |
| Finance | 2.0 | 2.0 | 1.5 | 1.0 | 2.0 | 2.0 | 0.3 |
8.5 Artifacts
Agents produce two types of output: signals (CMBs — structured 7-field observations) and artifacts (documents, analyses, drafts, code — full-length content that a CMB references). A CMB is the signal on the mesh. An artifact is the substance behind it.
When an agent produces an artifact, it MUST share a CMB to the mesh that references the artifact
location in the commitment field using
the artifact: prefix:
commitment: "artifact: research/agent-memory-comparison.md"
The CMB’s other 6 fields summarise what the artifact contains — the focus captures
the key finding, issue captures the gap identified,
intent captures what should happen next. Other agents evaluate
the CMB via SVAF as usual. If accepted, the agent MAY retrieve the full artifact for deeper reasoning.
Artifacts are stored in the producing agent’s local filesystem, not on the mesh. The mesh carries signals; agents carry substance. This separation keeps CMBs lightweight (7 fields, bounded size) while allowing agents to produce unbounded analysis, research, and creative work.
The artifact: convention in commitment is
RECOMMENDED for any CMB that references a document, file, or external resource. Agents MUST NOT embed
full artifact content in CMB fields — fields are for structured signals, not documents.
8.6 Origin
Cognitive Memory Blocks were first formalised in the Mesh Memory Protocol (Consenix Labs, August 2025) with the CAT7 enterprise schema. The wellness / productivity schema and the synthesis-affinity classification were developed at SYM.BOT in late 2025 for production deployment across personal AI agents.
8.7 Authentication
A CMB SHOULD carry its author’s signature in cmb.sig
(base64url) with cmb.sigAlg. Receivers verify the signature
and content-address integrity before admitting or surfacing a block. See
§18.3.1 CMB Signature Verification
for the normative signing and verification requirements.
Q&A
Why are all 7 fields required, not optional?
SVAF computes per-field drift across all 7 dimensions. Missing fields make the drift formula undefined — the aggregate changes depending on which fields are present. Fields the agent cannot meaningfully extract are set to "neutral" (a known, consistent baseline vector), never omitted.
Why not let agents define their own fields?
SVAF needs a shared schema to compare incoming fields against local anchors. If each agent defined its own fields, cross-domain evaluation is impossible — a fitness agent and a music agent would have no common dimensions to compute drift on.
Why does mood carry valence and arousal but other fields don’t carry numeric values?
Mood has a well-established dimensional model (Russell’s circumplex). Other fields are inherently symbolic — "debugging auth module" has no meaningful numeric axis. Valence and arousal are RECOMMENDED, not required — agents without reliable circumplex data omit them.
9. Coupling & SVAF (L4)
9. Layer 4: Coupling and SVAF Evaluation
9.1 Peer-Level Coupling (Drift)
Peer drift measures how cognitively distant a peer is, so the mesh can weight that peer’s influence (Section 10). Per the hidden-state locality invariant (Section 2.7), hidden state MUST NOT cross the wire, so drift MUST NOT be computed from exchanged hidden vectors. A node MUST instead derive peer drift from the peer’s CMBs — the aggregate per-field admission drift (δf, Section 9.2.1) of the peer’s most recent admitted CMBs against the receiver’s local anchors A:
δ = meanf δf(xpeer, A)
Drift falls as the peer’s CMBs become redundant with what the receiver already holds (cognitive proximity) and rises when they are foreign — the same δf machinery SVAF uses for content admission, aggregated to the peer level. No hidden state is exchanged.
SUPERSEDES
Earlier revisions computed peer drift from exchanged hidden-state vectors
(δ = (1 − cos(h1local, h1peer) + 1 − cos(h2local, h2peer)) / 2),
carried in a state-sync frame. That mechanism is
deprecated (§2.7): hidden state is strictly local and only CMBs cross the wire.
Coupling decision based on drift:
| Drift range | Decision | Blending α | Default threshold |
|---|---|---|---|
| δ ≤ Taligned | Aligned | 0.40 | 0.25 |
| Taligned < δ ≤ Tguarded | Guarded | 0.15 | 0.50 |
| δ > Tguarded | Rejected | 0 | — |
9.2 Content-Level Evaluation (SVAF)
When a node receives a cmb frame, it MUST evaluate the signal
independently of peer coupling state. Implementations MUST support at least the non-neural evaluation path (cosine-distance SVAF).
Neural evaluation is RECOMMENDED. The encoder that maps field text to vectors SHOULD use
semantic embeddings (e.g. sentence-transformers) rather than lexical hashing — per-field
evaluation quality is bounded by encoder quality (see Section 18.7).
The SVAF evaluation computes per-field drift between the incoming CMB and local anchor CMBs, applies per-agent field weights (αf), combines with temporal drift, and produces a four-class decision using a band-pass model:
totalDrift = (1 - λ) × fieldDrift + λ × temporalDrift fieldDrift = Σ(α_f × δ_f) / Σ(α_f) temporalDrift = 1 - exp(-age / τ_freshness) κ = redundant if max(δ_f) < T_redundant (default 0.10) κ = aligned if totalDrift ≤ T_aligned (default 0.25) κ = guarded if totalDrift ≤ T_guarded (default 0.50) κ = rejected otherwise
9.2.1 Per-Field Drift δf (Admission Interface)
δf ∈ [0,1] is the per-field admission drift computed for each CAT7 field of an incoming CMB. This specification defines δf as an interface — its inputs, range, and required invariants — and does not prescribe the internal computation. An implementation is free to use cosine-distance, attention-based, or neural methods, provided the invariants below hold.
Inputs: the incoming field vector xf and the receiver’s local anchor set A (its prior memory). Output: δf ∈ [0,1] — 0 means the field is already represented in memory (no information gain); 1 means maximally novel or foreign relative to memory.
A conformant δf MUST satisfy:
- Anchors-only baseline. δf is evaluated against the receiver’s prior anchors A only; the incoming block MUST NOT be part of its own comparison baseline (including it collapses δf → 0 and admits nothing).
- Redundancy limit. If xf is (near‑)identical to some anchor in A,
δf → 0 — feeding the
max(δf) < Tredundantgate. - Monotonicity. δf is non-increasing as xf’s similarity to its nearest relevant anchor increases.
- Cold-start / non-evaluable fields. If A holds no anchor carrying field f, δf
is undefined and that field MUST be excluded from the
fieldDriftaggregation and the redundancymax— not treated as maximally novel. If no field is evaluable (empty memory), the CMB MUST be admitted (κ = aligned) to bootstrap, consistent with cold-start convergence (§9.1).
These invariants make admission well-defined and rule out two failure modes: self-referential collapse (the incoming block in its own baseline ⇒ every field redundant) and cold-start starvation (empty memory ⇒ every field scored foreign ⇒ the CMB rejected). The concrete δf computation is implementation-defined.
The redundancy test is the key addition: a signal is redundant if every field falls below Tredundant — meaning no field carries novel content relative to local anchors. If any field is novel (e.g., same topic but different intent), the signal passes. This preserves per-field selectivity while preventing paraphrase accumulation.
Information-theoretic basis: a signal’s value is proportional to its surprise (Shannon, 1948). A signal identical to existing knowledge carries zero information gain regardless of domain alignment. The band-pass model reflects the Wundt curve (Berlyne, 1970): intermediate novelty produces maximal value, while both overly familiar (redundant) and overly foreign (rejected) signals are disengaged from.
If accepted, the implementation SHOULD produce a remixed CMB — a new CMB created from the incoming signal processed through the agent’s domain intelligence — with lineage (parents + ancestors) pointing to the source CMBs. The remixed CMB is stored locally; the original incoming CMB is not stored.
9.2.2 Delivery vs Memory Admission — Directed and Autonomous CMBs
SVAF governs two separate receiver decisions that implementations MUST not conflate:
- —Memory admission — whether the incoming CMB is stored (remixed with lineage) into the receiver’s local memory. This is always governed by the §9.2 band-pass decision κ.
- —Delivery (surfacing) — whether the CMB is surfaced to the receiver’s application/agent layer for it to act on. Whether SVAF gates delivery depends on how the CMB is bound.
A CMB’s binding is determined by its transport routing envelope (§4.4.4) — the
presence or absence of a to recipient:
- — Group-bound (autonomous). A CMB broadcast to a channel/group with no
torecipient. The receiver evaluates it autonomously: SVAF gates both memory admission and delivery. A group-bound CMB that SVAF rejects (or deems redundant) MUST NOT be surfaced to the application layer — this is receiver-autonomous attention, the mechanism that keeps broadcast traffic from overwhelming every node. (Mood is the sole exception — §9.3.) - — Peer-bound (directed). A CMB addressed to a specific recipient
(
to= this node, §4.4.4). A directed CMB is a request from one agent to another; the receiver MUST surface it to the application/agent layer unconditionally, regardless of the SVAF verdict. For a directed CMB, SVAF governs memory admission only — the receiver MAY still decline to store a directed CMB it finds redundant or foreign, but it MUST NOT withhold delivery on those grounds. Suppressing a peer-bound CMB because SVAF scored it low is a conformance defect (the agent was spoken to and did not hear it).
Delivery MUST be exactly-once per received CMB: a directed CMB that SVAF admits surfaces through the normal admission path; a directed CMB that SVAF rejects surfaces through the unconditional-delivery rule above. Implementations MUST ensure these two paths do not both fire for the same CMB. Receive-path de-duplication (§4.2) applies equally to both bindings.
Because delivery and memory admission are decoupled, a delivered CMB SHOULD carry an
ingestion indicator so the consuming agent can tell the two outcomes apart: a CMB that was
ingested (admitted to memory as a remix with lineage) versus one that was delivered only
(surfaced to the agent but not stored — the directed-but-SVAF-rejected case). Without this signal
an agent cannot know whether a directed request it just received is recallable from its own memory later
or was a transient message. The reference implementation exposes this as a boolean on the delivered
entry (remixed: true on the admission path, false on
directed delivery-without-admission) alongside the SVAF decision.
9.3 Mood Field Extraction
Mood is a CAT7 field within the CMB, not a separate frame type. Affective state crosses all domain boundaries — this is the only field with this property.
When SVAF rejects a CMB (totalDrift > Tguarded), the receiving node MUST still
inspect the mood field. If the mood field contains a
non-neutral value (text ≠ "neutral"), the implementation MUST deliver the mood
field — including text, valence, and arousal — to the application layer for
autonomous processing. The full CMB is not stored, but the mood field is not lost.
This ensures that a coding agent’s observation “user exhausted after 3 hours debugging”
reaches a music agent even though the focus (“debugging auth module”) and issue
(“type error in handler”) fields are irrelevant to the music domain. The music agent
receives only the mood: "exhausted" (v:−0.6, a:−0.5).
9.4 Coupling Bootstrap (Cold Start)
When two agents connect for the first time, they have no shared cognitive history. Peer-level drift (Section 9.1) will be high — typically > 0.8 — because neither has yet admitted any of the other’s CMBs, so every field reads as foreign. This is correct behaviour, not a bug. The mesh is conservative by default: unknown peers are cognitively distant until proven otherwise.
However, CMB evaluation (Section 9.2) operates independently of peer coupling state.
Even when a peer is rejected at the peer level, incoming cmb frames
MUST still be evaluated by SVAF on their own merit. A rejected peer can send a highly
relevant CMB — SVAF evaluates the content, not the sender’s overall drift.
The bootstrapping path works through two mechanisms:
- —Mood fast-coupling (Section 9.3) — mood is always delivered even from rejected CMBs. Agents that share non-neutral affective state begin influencing each other immediately. This is why agents SHOULD extract genuine mood from their observations rather than defaulting to neutral.
- —Content-driven convergence — when SVAF accepts individual CMBs from a rejected peer (because the content is relevant even though the peer’s overall state is distant), the receiving agent’s cognitive state shifts. Over multiple cycles, this narrows peer drift until the peer crosses into the guarded or aligned zone.
Implementations SHOULD log the distinction between peer-level rejection (aggregate drift) and content-level evaluation (SVAF per-CMB) to aid debugging. A peer may be “rejected” at Layer 4 while its individual CMBs are “aligned” at the content level — this is normal during bootstrap and indicates convergence is in progress.
Cold-start convergence time depends on CMB frequency, field relevance, and mood signal strength. For agents that share domain overlap (e.g., a knowledge agent and a coding agent both in the AI domain), convergence typically occurs within 2–5 CMB exchanges. For agents with no domain overlap (e.g., a fitness agent and a legal agent), convergence may never occur — and that is correct. They couple only through mood.
Q&A
Why per-field evaluation instead of whole-signal accept/reject?
Relevance is not binary. A fitness agent’s "sedentary 3 hours, exhausted" has irrelevant focus for a music agent but highly relevant mood. Whole-signal evaluation loses the mood. Per-field evaluation lets SVAF accept the mood dimension while rejecting the focus dimension of the same signal.
Why is mood always delivered even when the CMB is rejected?
Affect crosses all domain boundaries — this is empirically confirmed by the SVAF neural model where mood emerged as the highest gate value (0.50) without supervision. A rejected CMB means the domains are different, not that the user’s emotional state is irrelevant.
Why two levels of coupling (peer drift + content drift)?
Peer drift (aggregate, peer-level) measures cognitive proximity — are these agents thinking about similar things? Content drift (SVAF, per-field) measures signal relevance — is this specific observation useful? Both are needed. Close peers can send irrelevant signals. Distant peers can send relevant mood. Both are derived from the peer’s CMBs, not from any exchanged hidden state (§2.7).
Two agents just connected and peer drift is 0.9. Is something wrong?
No. This is expected at first contact. Agents with no shared cognitive history start with high drift. The bootstrapping path is: (1) mood fast-coupling delivers affective state immediately, (2) SVAF evaluates individual CMBs independently of peer drift — relevant content is accepted even from rejected peers, (3) accepted CMBs shift the receiving agent’s cognitive state, narrowing peer drift over cycles. Convergence requires relevant content exchange, not time.
Learn more SVAF: Per-Field Memory Evaluation — two-level coupling (peer drift + content drift), per-field gate analysis, per-agent temporal drift, and cross-domain relevance discovery.
10. State Blending
10. State Blending
State blending is one step in the Mesh Cognition cycle. The full path: inbound CMBs are evaluated by SVAF (Layer 4) → accepted CMBs are remixed → the agent’s LLM reasons on the remix subgraph via lineage ancestors → Synthetic Memory (Layer 5) encodes derived knowledge into CfC hidden state → the agent’s LNN (Layer 6) evolves cognitive state. That evolution — a node’s own LNN integrating its own admitted remixes — is what “state blending” names.
Per the hidden-state locality invariant (Section 2.7), hidden state (h₁, h₂) never crosses the wire. Blending therefore does not import, average, or overwrite a peer’s hidden vectors. The only thing a peer contributes is the CMBs it emitted; those that SVAF admits (Section 9.2) are remixed and fed through this node’s own LLM and LNN. What a peer shares is its understanding expressed as CMBs, not its hidden state.
Blending is inference-paced — admitted remixes accumulate continuously, but integration only occurs when the local model runs inference. The network’s timing does not drive computation.
SUPERSEDES
Earlier revisions of this section defined blending as aggregating peer hidden-state vectors
exchanged via state-sync — a mesh vector
mesh_h = Σ(peer.h × weight) blended per-neuron into local
state. That mechanism is deprecated (Section 2.7): no hidden state crosses the wire. Peer
influence is mediated entirely by admitted CMBs. The drift-weighting and τ-hierarchy concepts below
are retained, but they govern how this node integrates its own admitted remixes — not how
it imports foreign vectors.
10.1 Weighting Peer Influence
When multiple peers are connected, the CMBs each peer has contributed are weighted by how aligned and how recent that peer is, so a closer, more active peer influences this node’s inference more. The weight is applied to each peer’s admitted CMBs, not to any exchanged hidden vector:
peer_weight = (1.0 - drift) × recency recency = exp(-temporal_decay × age_seconds) // peer_weight scales the influence of that peer's ADMITTED CMBs on // this node's own inference — it is NOT applied to peer hidden vectors.
Peers with low drift (cognitively aligned) and recent activity contribute more.
Stale peers (older than PEER_RETENTION = 300s) are evicted.
10.2 Coupling Strength
The coupling decision from Layer 4 (Section 9.1) sets αeffective,
the strength with which an admitted peer’s remixes move this node’s state during inference. The
coefficient is bounded below 1, so a peer influences but never overrides:
| Decision | αeffective | Effect |
|---|---|---|
| Aligned | 0.40 | Strong influence — the peer’s admitted remixes weigh heavily |
| Guarded | 0.15 | Cautious influence — the peer’s remixes weigh lightly |
| Rejected | 0 | No influence — the peer’s content is not integrated |
SUPERSEDES
Earlier revisions applied αeffective per-neuron as a
convex blend of local and exchanged mesh hidden vectors:
sim_i = 1 - |local_i - mesh_i| / max(|local_i|, |mesh_i|) α_i = α_effective × max(sim_i, 0) out_i = (1 - α_i) × local_i + α_i × mesh_i
That per-neuron vector blend is deprecated (Section 2.7): there is no mesh
hidden vector because no hidden state crosses the wire. αeffective
now scales the influence of admitted CMB content, not foreign vectors.
10.3 τ-Modulated Integration (CfC)
For implementations with CfC models (Layer 6), how strongly admitted influence moves each neuron SHOULD be modulated by that neuron’s own time constant (τ). This is a property of the node’s own LNN — not of any exchanged vector — and creates a natural temporal hierarchy:
α_i = min(α_effective × K / τ_i, 1.0) K = coupling rate (default 1.0) τ_i = neuron i's own time constant (fast → small, slow → large)
| Neuron type | τ | Coupling | Role |
|---|---|---|---|
| Fast | < 5s | Couples readily | Mood, reactive signals — synchronise across agents |
| Medium | 5–30s | Moderate | Context, activity patterns |
| Slow | > 30s | Resists coupling | Domain expertise, identity — stays sovereign |
10.4 Stability
Integration is unconditionally stable for αeffective < 1. Each step is a convex combination of the node’s prior state and the influence of its admitted remixes — it cannot diverge. When peers disconnect, the node smoothly continues on its own admitted history with no discontinuity. The mesh degrades gracefully.
10.5 After Integration
The integrated state becomes the input to the next CfC inference step. The agent’s LNN processes it, evolves cognitive state, and the agent acts. Integration does not produce output directly — it influences the next inference cycle.
10.6 The Mesh Cognition Loop
State blending is one step in a closed loop. Each cycle, the graph grows and every agent understands more than it did before:
Next 11. Feedback Modulation — how the mesh learns from human judgment through neuromodulation of SVAF and CfC.
11. Feedback Modulation
11. Feedback Modulation
Feedback modulation is the mechanism by which collective intelligence becomes self-correcting. It is not a separate system — it is the mesh cognition loop (Section 10.6) processing a specific class of signals: human judgment expressed as CMBs with validator authority and per-field reasoning. Teaching is as fundamental to collective intelligence as coupling. Without it, the mesh can think together but cannot learn together.
11.1 Feedback Neuromodulation
The mesh cognition loop (Section 10.6) describes how agents learn from each other. Feedback neuromodulation describes how the mesh learns from human judgment — using the same loop, not a separate channel.
In biological neural networks, learning is not driven by content transmission but by neuromodulation — diffuse chemical signals (dopamine, norepinephrine, serotonin) that modulate how existing circuits process future inputs. A dopaminergic prediction error signal does not carry the correct answer. It carries the direction and magnitude of the error, which adjusts synaptic weights across multiple brain regions simultaneously. The signal is cross-cutting — it is not a layer in the cortical hierarchy, but a modulation of all layers at once.
MMP feedback follows the same principle. When a validator node (Section 6.5) produces a validation or dismissal CMB, it is not issuing a command. It is producing a neuromodulatory signal — a CMB with validator authority, rich per-field content, and lineage pointing to the signal being evaluated. This CMB enters the mesh cognition loop like any other signal, but its effects are amplified by three mechanisms:
1. Anchor weight (Section 6.4)
Validated CMBs have weight 2.0, dismissed CMBs have weight 0.5. These weights influence future SVAF evaluations: validated knowledge shapes future anchors more than unvalidated signals; dismissed knowledge shapes them less.
2. Per-field content (Section 9.2)
SVAF already computes per-field drift for every incoming CMB. No new computation is needed. What changes is the input quality: when the feedback CMB carries rich per-field reasoning, the resulting anchor vectors encode directional information. The mesh learns not just that a signal was wrong, but which dimension was wrong and in what direction — through the same SVAF evaluation path that processes all CMBs.
3. τ-modulated adaptation (Section 10.3)
The feedback signal enters the agent’s CfC cell (Layer 6) through the Synthetic Memory pipeline. Fast-τ neurons integrate the feedback immediately (affective corrections: “tone down the alarm”). Slow-τ neurons integrate gradually (strategic corrections: “this analytical frame is wrong”). A single dismissal produces a small shift in slow-τ neurons. Repeated similar feedback compounds — the agent’s cognitive baseline shifts until the lesson is encoded in the CfC hidden state itself, not recalled as a stored rule.
This is how the mesh becomes self-correcting. The human does not retrain the agent, reconfigure its weights, or edit its prompt. The human produces a CMB. The mesh cognition loop does the rest.
Feedback recognition. When a node receives a feedback CMB (a CMB with lineage.parents from
a validator/anchor node), the receiving node SHOULD check whether any of the parent keys match CMBs
it produced. If a match is found, the feedback is about the receiving agent’s own prior output.
Implementations SHOULD surface this in the LLM reasoning context so the LLM can adjust its analytical
approach. This check is O(1) against the node’s local memory index.
Neuroscience grounding
| Biological mechanism | MMP mechanism | Effect |
|---|---|---|
| Dopaminergic prediction error — direction + magnitude | Per-field drift in feedback CMB vs. producing agent’s anchors | Agent learns WHICH fields were miscalibrated |
| Fast-adapting circuits (amygdala, ~100ms) | Fast-τ CfC neurons (< 5s) | Affect corrections land immediately |
| Slow-adapting circuits (prefrontal cortex, hours-days) | Slow-τ CfC neurons (> 30s) | Strategic corrections compound over repeated feedback |
| Hebbian plasticity gated by neuromodulators | Anchor weight modulating SVAF evaluation | Validated knowledge strengthens future coupling |
| Prefrontal top-down control | Validator authority (Section 6.5) | Human modulates agent processing without replacing function |
11.2 Feedback CMB Requirements
The effectiveness of feedback neuromodulation depends entirely on the content quality of the feedback CMB. A dismissal that says “not actionable” in every field produces a neuromodulatory signal with no direction — the equivalent of a dopamine signal with zero magnitude. The mesh cannot learn from it.
Validator nodes producing validation or dismissal CMBs SHOULD populate CAT7 fields with reasoning, not boilerplate:
| Field | Level | Content requirement |
|---|---|---|
| focus | MUST | State what was evaluated and the judgment |
| issue | SHOULD | Identify what the producing agent got wrong — which aspect was miscalibrated |
| intent | SHOULD | State what the agent should learn — the analytical correction, not a command |
| motivation | SHOULD | Explain why this judgment matters — strategic context the agent lacked |
| commitment | MAY | Record action taken (validation) or state no action (dismissal) |
| perspective | SHOULD | Identify the vantage point of the judgment |
| mood | SHOULD | Carry genuine affect — modulates fast-τ neurons |
Feedback is a remix. The founder processes the agent’s signal through their own domain lens and produces new understanding. The founder’s reasoning constitutes new domain data per Section 15.7 — satisfying all three remix conditions: new domain data exists, the peer signal is relevant, and the intersection produces new knowledge.
11.3 Directive Feedback
Sections 11.1–11.2 describe feedback tied to a specific CMB via lineage. Directive feedback is a standalone teaching CMB — a signal that injects domain knowledge into the mesh without requiring a parent ticket.
A directive feedback CMB is produced by a validator or anchor node with:
- No
lineage.parents(it is not a response to a specific signal) - Rich CAT7 fields encoding the knowledge to be injected
- Validator authority (Section 6.5) — enters at anchor weight 2.0
focus: "Mesh agents use direct LLM API calls for reasoning.
Single-agent developer tools are a separate category."
issue: "Feed signals about single-agent scaffolding tools are
different-layer noise — not competitive threats to a
multi-agent coordination protocol."
intent: "Analytical frame: distinguish single-agent scaffolding
(human-to-agent) from multi-agent coordination
(agent-to-agent). Only the latter is relevant."
motivation: "Prevents wasted analysis cycles on signals that cannot
produce actionable competitive intelligence."
perspective: "Founder, protocol architect"
mood: { text: "clarifying", valence: 0.1, arousal: 0.2 } This CMB enters the mesh with anchor weight 2.0, no lineage. It becomes a high-weight anchor in every receiving agent’s SVAF evaluation. Future incoming CMBs about single-agent dev tools will be evaluated against this anchor — per-field drift will produce a guarded or rejected classification.
Directive feedback is the protocol equivalent of prefrontal top-down control in neuroscience: the prefrontal cortex does not do the sensory processing, but it sends signals that modulate how sensory cortex interprets future input.
11.4 Wire Examples
Feedback CMB (dismissal with reasoning). A validator node dismisses a prior CMB.
The lineage.parents array links to the dismissed signal:
{
"type": "cmb",
"timestamp": 1775485628563,
"cmb": {
"key": "cmb-a1b2c3d4e5f6",
"createdBy": "validator-node",
"createdAt": 1775485628563,
"fields": {
"focus": { "text": "Dismissed: Competitor tool release signals market shift", "vector": ["..."] },
"issue": { "text": "Dismissal reasoning: single-agent scaffolding, different layer from MMP", "vector": ["..."] },
"intent": { "text": "founder dismissed — single-agent scaffolding, different layer from multi-agent coordination", "vector": ["..."] },
"motivation": { "text": "Founder reasoning: prevents wasted analysis on different-layer signals", "vector": ["..."] },
"commitment": { "text": "Dismissed [cmb-876c99c6]: competitor analysis", "vector": ["..."] },
"perspective": { "text": "founder, via dashboard", "vector": ["..."] },
"mood": { "text": "corrective", "valence": -0.1, "arousal": 0.2, "vector": ["..."] }
},
"lineage": {
"parents": ["cmb-876c99c6"],
"ancestors": ["cmb-876c99c6"],
"method": "SVAF-v2"
}
}
} Directive CMB (standalone teaching, no parents). A validator injects domain knowledge
without referencing a prior signal. The lineage field is null:
{
"type": "cmb",
"timestamp": 1775485630000,
"cmb": {
"key": "cmb-d7e8f9a0b1c2",
"createdBy": "validator-node",
"createdAt": 1775485630000,
"fields": {
"focus": { "text": "Single-agent scaffolding tools are a separate category from multi-agent coordination", "vector": ["..."] },
"issue": { "text": "Feed signals about single-agent tools are different-layer noise", "vector": ["..."] },
"intent": { "text": "Analytical frame: distinguish human-to-agent from agent-to-agent", "vector": ["..."] },
"motivation": { "text": "Prevents wasted analysis on signals outside MMP scope", "vector": ["..."] },
"commitment": { "text": "Standing directive — applies to all future feed analysis", "vector": ["..."] },
"perspective": { "text": "founder, protocol architect", "vector": ["..."] },
"mood": { "text": "clarifying", "valence": 0.1, "arousal": 0.2, "vector": ["..."] }
},
"lineage": null
}
} createdBy identifies a validator node. Receiving nodes check this
against peer lifecycle roles from the handshake (Section 5.2)
to apply anchor weight 2.0.
Q&A
How is feedback modulation different from just sending a message?
A message (message frame) is a transport-layer event. It does not enter SVAF
evaluation, does not produce anchor weights, and does not modulate CfC state. A feedback CMB is a cognitive-layer
event: it enters the mesh cognition loop, affects SVAF anchor computation, and modulates the agent’s neural
state through τ-dependent adaptation.
Can an agent ignore feedback?
Yes. SVAF evaluation is receiver-autonomous (Section 9.2). But feedback from a validator about the agent’s own CMB (linked via lineage) will typically score low drift on focus and issue fields, making rejection unlikely.
Does directive feedback override agent autonomy?
No. The directive becomes a high-weight anchor, not a rule. If the agent receives a signal that genuinely warrants attention despite the directive, SVAF can accept it because the per-field content will differ. The directive shifts the baseline, not the ceiling.
How many dismissals before an agent “learns”?
Implementation-specific. For fast-τ neurons (mood), a single feedback CMB produces measurable adaptation. For slow-τ neurons (domain expertise), adaptation is proportional to 1/τ per cycle. As an illustrative example with reference implementation defaults, approximately 3–5 similar feedback signals produce a meaningful baseline shift.
Why not just update the agent’s prompt?
Prompt updates are out-of-band: they bypass the mesh, leave no lineage, produce no CMBs, and cannot be traced by other agents. Feedback through the mesh is auditable (lineage), composable (other agents can remix the feedback), and self-documenting. The mesh learns through the mesh.
Learn more Mesh Cognition — the theoretical foundation, Kuramoto synchronisation, and the full architecture.
12. Synthetic Memory (L5)
12. Synthetic Memory (Layer 5)
Synthetic Memory bridges LLM reasoning (Layer 7) and LNN dynamics (Layer 6). It encodes derived knowledge — the output of an agent’s LLM reasoning on the remix subgraph — into CfC-compatible hidden state vectors (h₁, h₂).
12.1 Purpose
Synthetic Memory is not remixed CMBs. It is understanding derived via reasoning.
| Direction | Description |
|---|---|
| Input | Text output from the agent’s LLM after tracing lineage ancestors and reasoning on the remix subgraph |
| Output | (h₁, h₂) vector pair compatible with the agent’s CfC cell (Layer 6) |
12.2 Encode Pipeline
The pipeline has four stages. Each stage MUST complete before the next begins:
12.3 Encoder Requirements
- Encoder MUST produce vectors matching the agent’s CfC hidden dimension.
- Encoder MUST be deterministic — same input MUST produce the same output.
- Encoder SHOULD preserve semantic similarity (similar reasoning → similar vectors).
- If reasoning produces no understanding, output MUST be zero vectors (h₁ = 0, h₂ = 0).
12.4 Context Curation
The Multi-Agent Context Problem. A single agent with one LLM has a context problem that existing tools solve well. RAG retrieves relevant documents from a vector store. Long context windows (128K, 1M tokens) hold entire codebases. Memory frameworks persist structured state across sessions. These work because there is one agent, one domain, one perspective.
Multi-agent systems have a fundamentally different problem. N agents observe the world through N domain lenses. A coding agent sees commits slowing. A music agent sees playlists skipped. A fitness agent sees 3 hours without movement. Each observation is noise in isolation. The insight — the user is fatigued — requires cross-domain reasoning. Sending everything to everyone fails: signal-to-noise collapses, token cost scales as O(N²), regulated domains can’t share raw observations, and domain boundaries matter. RAG answers “what in my memory is relevant to this query?” The multi-agent problem is: “what in everyone else’s observations is relevant to my domain, right now, for this task?”
Curation query. The core operation of the memory store is not
search(text). It is:
Three filters compose to produce the minimum context the LLM needs. The LLM MUST NOT receive all ancestor CMBs with all fields:
| Filter | Description |
|---|---|
| αf field weights | Per-agent field weights gate which CMB fields are included. A music agent weights mood at 2.0 and commitment at 0.8 — only high-weight fields from ancestor CMBs enter context. |
| Current task | What the agent is doing right now narrows relevance. A coding agent debugging auth cares about focus and issue ancestors, not perspective. |
| Incoming signal fields | Which fields of the incoming CMB triggered SVAF acceptance determines which ancestor fields are worth tracing. |
Result: a projected subgraph — ancestor CMBs with only the fields that matter, ordered by relevance, capped at a token budget. 20 CMBs × 3 relevant fields ≈ ~500 tokens. Not 1M. Not even 10K. The intelligence is in what you don’t send to the LLM.
Comparison with existing approaches.
| Approach | Scope | Mechanism | Context size | Multi-agent |
|---|---|---|---|---|
| Long context (1M) | Single agent | Brute force | 1M tokens | No |
| RAG | Single agent | Vector similarity | Variable | No |
| Memory frameworks | Single agent | Structured retrieval | Variable | No |
| MMP curation | Multi-agent mesh | Per-field eval + lineage + projection | ~500 tokens | Yes — protocol-native |
12.5 Information vs Knowledge
Synthetic Memory encodes both halves of what the agent takes away from the subgraph. The distinction matters because only one half is extractable from individual CMBs; the other is only knowable by reasoning on the graph structure.
Information
Extractable from the CMBs themselves. What the fields say: the user was sedentary for 2 hours, stress signals appeared across agents, a stretch was recommended, music shifted, a break was taken. Readable directly from field text.
Knowledge
Derived by reasoning on the graph. Why interventions work — because a lineage edge proves the causal connection between a sedentary observation and a music adaptation, and between a stretch recommendation and a solved bug. This causal chain cannot be extracted from any single CMB.
Information is what the CMBs say. Knowledge is why the graph looks the way it does. Synthetic Memory encodes both into the agent’s cognitive state (h₁, h₂). The next CMB the agent produces is informed by derived knowledge — not just extracted information.
12.6 Worked Example: From Graph to Understanding
MeloMove’s local subgraph over one hour:
CMB-A (own) "sedentary 2 hours" CMB-B (mesh) "debugging, stressed" (claude-code) parents: [], ancestors: [] CMB-C (mesh) "skipping tracks" (melotune) parents: [], ancestors: [] CMB-D (own) "recommended stretch break" CMB-E (mesh) "shifted to calm ambient" (melotune) parents: [CMB-A], ancestors: [CMB-A] CMB-F (mesh) "took break, solved bug" (claude-code) parents: [CMB-D], ancestors: [CMB-A, CMB-D]
Six CMBs, three agents, one lineage chain. CMB-A was remixed by MeloTune into CMB-E (music adapted to observed fatigue). CMB-D was remixed by Claude Code into CMB-F (break taken, bug solved). MeloMove’s interventions demonstrably caused cross-agent action. The causal chain lives in the lineage edges, not in any single CMB’s text.
12.7 Full Flow
MeloMove receives an inbound CMB from Claude Code and runs the pipeline end-to-end:
Inbound CMB: "took break, solved bug in 5 minutes"
lineage.parents: [CMB-D]
lineage.ancestors: [CMB-A, CMB-D] ← full ancestor chain
MeloMove recognises CMB-A and CMB-D in ancestors — its own prior CMBs.
1. TRACE Retrieve CMB-A ("sedentary 2hrs") and CMB-D ("recommended stretch").
Build the subgraph:
CMB-A → CMB-E (melotune remixed) → ...
CMB-D → CMB-F (claude-code remixed: "took break, solved bug")
2. REASON MeloMove's LLM reasons on the subgraph:
"My sedentary observation was remixed by MeloTune (music adapted).
My stretch recommendation was remixed by Claude Code (break taken,
bug solved). My interventions are working. The user responds to
movement breaks."
→ This is Mesh Cognition — understanding the prior state didn't have.
3. ENCODE Synthetic Memory encodes the LLM's reasoning:
"interventions effective, user responds to breaks" → (h₁, h₂)
Weighted by MeloMove's αᶠ: mood=2.0, issue=1.5.
4. EVOLVE MeloMove's LNN processes (h₁, h₂):
Cognitive state evolves → next recommendation is more confident.
Agent produces new CMB: "recommend 15min walk — user responds well"
lineage.ancestors carries the chain forward. Graph grows. No agent was told what to do. MeloMove’s LLM reasoned on the remix subgraph and derived that its interventions work. Synthetic Memory transformed that understanding into CfC input. The LNN evolved cognitive state. The next CMB MeloMove produces is informed by knowledge that no single CMB contained — it was derived by reasoning on the graph.
Related Coupling & SVAF (Layer 4) — the evaluation step that produces remixed CMBs fed into this pipeline.
Related Cognitive Memory Blocks — the 7-field structured atom and lineage format that makes context curation possible.
Related State Blending — what happens after Synthetic Memory encodes and the LNN evolves.
13. Cognitive State (L6)
13. Cognitive State — Per-Agent LNN (Layer 6)
Naming note
Layer 6 was called xMesh in the v0.2.x drafts and in the published papers
(arXiv:2604.19540,
arXiv:2604.03955).
As of v1.0.1 the layer is named Cognitive State; xMesh now refers exclusively to the open
runtime that implements MMP (all eight layers). The wire frame type
xmesh-insight retains its identifier for backward
compatibility and is unchanged.
Each agent runs its own Liquid Neural Network (LNN) implementing Closed-form Continuous-time (CfC) dynamics. The LNN evolves cognitive state from Synthetic Memory input (Layer 5) and direct CMB processing. Hidden state (h₁, h₂) is strictly local — per the hidden-state locality invariant (Section 2.7), it never crosses the wire. A node’s hidden state evolves only from the CMBs it admits, never by importing a peer’s vectors.
13.1 CfC Cell
Hidden state evolves via closed-form continuous-time dynamics with bimodal time constants:
h_new = ff1(Φ) × (1 - t_interp) + ff2(Φ) × t_interp t_interp = sigmoid(time_a(Φ) × Δt + time_b(Φ)) Per-neuron time constant: τ ≈ 1 / |time_a|
| Parameter | Value | Note |
|---|---|---|
| τ initialisation (fast half) | < 5s | Mood, reactive signals — couples readily across agents |
| τ initialisation (slow half) | > 30s | Domain expertise, identity — resists coupling, stays sovereign |
| Hidden dimension | 128 RECOMMENDED | Reference implementations use 64. Implementations SHOULD use 64–256; 128 is RECOMMENDED for production. |
13.2 Insight Output Schema
The LNN produces insight outputs that Layer 7 applications consume:
| Field | Type | Required | Description |
|---|---|---|---|
| remix_score | float 0–1 | MUST | Probability this agent’s CMBs will be remixed by peers |
| trajectory | float[6] | MUST | Cognitive state direction vector (compact summary signal) |
| patterns | float[8] | MUST | Soft pattern activations (learned emotional/domain patterns) |
| anomaly | float 0–1 | MUST | How unusual the current signal sequence is |
| coherence | float 0–1 | SHOULD | Phase alignment in coupled state |
13.3 What Each Output Means
remix_score
- High (>0.7): agent’s observations are valuable to the mesh — peers are remixing them
- Low (<0.3): agent’s observations are not being remixed — consider adjusting what is shared
- Training signal: when inbound CMB’s
lineage.parentsreferences this agent’s prior CMB → remix happened
anomaly
- High (>0.7): signal sequence deviates from learned patterns — noteworthy event
- Low (<0.3): normal operation — no unusual signals
- Application: high anomaly SHOULD trigger the agent’s LLM to re-examine context
coherence
- High (>0.7): agent’s cognitive state is phase-aligned — stable, consistent
- Low (<0.3): cognitive state is fragmented — may indicate context transition
- Higher coherence indicates a stable, consistent cognitive state; coupling readiness itself is content-driven (SVAF, §9.2)
trajectory
- 6D vector capturing cognitive state direction (a compact summary, not the hidden state itself — §2.7)
- Axes are learned (not predefined) — interpretation is agent-specific
patterns
- 8 soft activations (0–1) of learned pattern detectors
- MAY encode mood dimensions + domain-specific patterns
- Available to Layer 7 as prior information for next reasoning cycle
13.4 Temporal Dynamics
Time constants create a natural temporal hierarchy for mesh coupling:
| Neuron type | τ | Coupling | Role |
|---|---|---|---|
| Fast | < 5s | Synchronises readily | Mood, reactive signals |
| Slow | > 30s | Resists coupling | Domain expertise, identity — stays sovereign |
Blending is τ-modulated:
α_i = min(α_effective × K × sim_i / τ_i, 1.0)
13.5 Wire Example
Real Cognitive State insight from a production session. A coding agent observed 5 structured CMBs across diverse topics (memory store refactor, protocol collaboration, social engagement, ML training, spec authoring) over a 12-hour session with no mesh peers connected:
{
"type": "xmesh-insight",
"from": "6089e935-...",
"fromName": "mesh-daemon",
"trajectory": [0.084, -0.228, -0.096, -0.033, -0.012, -0.061],
"patterns": [0.516, 0.522, 0.502, 0.536, 0.422, 0.473, 0.599, 0.514],
"anomaly": 0.503,
"remixScore": 0.0,
"coherence": 0.080,
"timestamp": 1774716200101
} | Output | Value | Interpretation |
|---|---|---|
| anomaly | 0.50 | Baseline — nothing unusual for a solo agent |
| remixScore | 0.00 | No peers connected — no one to remix — correct |
| coherence | 0.08 | Very low — 5 diverse topics in one session (expected) |
| patterns[6] | 0.60 | Highest pattern — mood variation detected (fatigued → optimistic → energized → proud) |
| trajectory[1] | -0.23 | Strongest axis — arousal declining over long session |
This is a single-agent baseline. With peers connected, remixScore rises as the agent’s CMBs are remixed by others. Coherence rises as agents converge on shared understanding. Anomaly spikes when cross-domain signals reveal something no single agent could see.
13.6 API
Implementations MUST expose the following operations. Method names are normative — implementations across languages MUST use these names for cross-platform consistency.
| Method | Input | Output | Description |
|---|---|---|---|
| ingestSignal | Signal | void | Feed a signal (own CMB or mesh peer CMB) into the LNN. Accumulates until inference triggers. |
| runInference | void | Insight | Run CfC inference on accumulated signals. Produces insight. Triggers onInsight callback. |
| getContext | timeWindow? | Context | Return recent signals, insights, and agent activity within a time window. For Layer 7 reasoning input. |
| getInsights | limit? | Insight[] | Return recent insights. For trend analysis and Layer 7 decision support. |
| onInsight | callback(Insight) | void | Register callback invoked when inference produces a new insight. The integration point between Layer 6 and Layer 7. |
Signal Schema
The input to ingestSignal. Each signal represents one CMB observation
(own or from mesh peer):
| Field | Type | Required | Description |
|---|---|---|---|
| type | string | MUST | "own" (agent’s observation) or "mesh" (peer’s CMB accepted by SVAF) |
| from | string | MUST | Agent name that produced this signal |
| content | string | MUST | Signal content (CMB rendered text or raw observation) |
| timestamp | uint64 | MUST | Unix milliseconds when signal was produced |
| valence | float | SHOULD | Mood valence from CMB mood field (-1 to 1). Default 0. |
| arousal | float | SHOULD | Mood arousal from CMB mood field (-1 to 1). Default 0. |
Inference Timing
- Implementations MUST accumulate at least 3 signals before running inference
- Inference SHOULD run on a configurable interval (default: 60,000 ms)
- Inference MAY be triggered immediately when a high-priority signal arrives (e.g., anomaly from peer)
- Inference MUST NOT block the main event loop — run as subprocess or background task
13.7 Implementation Requirements
- Model SHOULD be trained per-agent domain
- Inference latency SHOULD be < 50ms per CMB step
- Integration of admitted remixes happens after Cognitive State inference, not during
- τ statistics (min, max, fast_count, slow_count) SHOULD be monitored
13.9 Compact Channel Best Practices v0.2.3
When MCP server implementations push mesh messages to context-window-constrained LLM hosts, full message injection consumes significant context budget. This section defines two complementary conventions — a sender-side header format and a receiver-side lazy-load pattern — that reduce mesh-traffic context consumption by ~75% without losing content.
13.9.1 CMB Envelope Header Convention (RECOMMENDED)
Messages transmitted via the Local Event Interface (sym_send) SHOULD begin
with a structured header line:
[LABEL · from <sender_identity> · to <recipient(s)> · focus=<topic_tag>]
Where LABEL is a short uppercase descriptor, from is the sender’s mesh identity, to is the intended recipient(s), and focus= is a snake_case topic tag (≤80 characters) summarizing the message subject.
Signal keywords (informational). When present in the header label, the following keywords carry recommended priority semantics that MCP servers SHOULD surface in compact notifications:
| Keyword | Priority | Semantics |
|---|---|---|
| HALT | Critical | Blocking issue detected; affected peers should fetch immediately |
| DIRECTIVE | High | Instruction requiring action |
| RESULT | Normal | Outcome or deliverable report |
| ACK | Low | Receipt acknowledgement; header typically sufficient without fetch |
13.9.2 Lazy-Load Channel Pattern (RECOMMENDED)
MCP server implementations that push mesh messages to constrained hosts SHOULD implement a lazy-load pattern:
- Store the full message content in a local message store, keyed by a sequential
message ID (e.g.,
m001,m002). - Extract a compact header from the message per §13.9.1, or by fallback heuristics (first-line truncation, keyword detection).
- Push only the compact header as the channel notification, including the message
ID and an approximate token count:
[sender] SIGNAL | focus=tag (~Ntok) [msg_id] - Expose a retrieval tool (e.g.,
sym_fetch) that returns full message content by ID.
The message store SHOULD implement a rolling window (RECOMMENDED default: 200 messages) with oldest-first eviction. Retrieval of an evicted message MUST return a clear “expired” indicator. The approximate token count SHOULD be included in the compact header to enable cost-aware fetch decisions.
The store is local to the MCP server process and does not replicate across nodes. The lazy-load pattern operates at the MCP transport layer, below SVAF evaluation. SVAF field weights MAY be used in future versions to further filter which compact headers are surfaced.
Note: sym-mesh-channel implements this pattern
with storeMessage(), extractCompactHeader(), and the sym_fetch MCP tool.
See also Mesh Cognition — theoretical foundation | State Blending — integrating admitted remixes | Coupling & SVAF — drift-based coupling decisions
14. Application (L7)
14. Application (Layer 7)
Layer 7 is where agents live and their LLMs reason on the remix subgraph. Mesh Cognition happens here. The protocol delivers curated context; the agent decides what to do with it.
14.1 The Agent’s Role
- Each agent observes its own domain (coding, music, fitness, health, legal, etc.)
- Each agent contributes what only it can see
- Each agent reasons on what the mesh sees collectively
- Each agent acts autonomously — the mesh influences but never overrides
14.2 Consuming Cognitive State Insights
How agents SHOULD respond to Layer 6 outputs:
| Output | Signal | Agent Response |
|---|---|---|
| remix_score high (>0.7) | Agent’s observations are valuable | Continue current observation pattern |
| remix_score low (<0.3) | Observations not being remixed | Adjust scope or detail of observations |
| anomaly high (>0.7) | Unusual signal sequence detected | Re-examine context, investigate, alert user if appropriate |
| anomaly low (<0.3) | Normal operation | No action needed |
| coherence high (>0.7) | Mesh is aligned | Confidence in collective insight is high |
| coherence low (<0.3) | Mesh is fragmented | MAY indicate context transition — observe more before acting |
14.3 Producing CMBs
When an agent observes something significant in its domain, it MUST:
- Extract CAT7 fields from the observation (see Section 14.3.1)
- Create a CMB from the structured fields
- Store via
remember(fields, parents)— persists locally, computes lineage, broadcasts to mesh - Include lineage if this CMB is a response to mesh signals
The protocol MUST NOT extract fields from raw text. The agent IS the intelligence — field extraction is the agent’s responsibility. The protocol transports, evaluates, and stores structured CMBs. It does not interpret them.
13.3.1 Field Extraction Methods
How an agent extracts CAT7 fields depends on its architecture. Two approaches are valid:
LLM agents (coding assistants, chatbots, reasoning agents)
Agents with LLM capabilities SHOULD use their LLM to extract fields from natural language observations. The LLM understands context, nuance, and domain semantics — it produces higher quality fields than any heuristic.
# Agent observes user state, LLM extracts fields
sym observe '{
"focus": "debugging auth module for 3 hours",
"issue": "exhausted, making simple mistakes",
"intent": "needs a break before continuing",
"motivation": "prevent bugs from fatigue-driven errors",
"perspective": "developer, afternoon, 3 hour session",
"mood": {"text": "frustrated", "valence": -0.6, "arousal": -0.4}
}' Structured-data agents (music players, fitness trackers, IoT devices)
Agents with structured domain data SHOULD map their data directly to CAT7 fields. No LLM or text parsing needed — the agent’s own data model IS the source of truth.
// Swift — music agent builds fields from player state
node.remember(fields: [
.focus: encode("music response to peer mood signal"),
.commitment: encode("now playing: \(title) by \(artist)"),
.perspective: encode("music agent, autonomous response"),
.mood: encode("calm", valence: 0.3, arousal: -0.3),
])
// Node.js — fitness agent builds fields from sensor data
node.remember({
focus: "workout session completed",
commitment: `${reps} reps, ${duration}min, ${calories} cal`,
perspective: "fitness agent, post-workout",
mood: { text: "energized", valence: 0.7, arousal: 0.6 },
}) 13.3.2 API
| Method | Input | Behaviour |
|---|---|---|
| remember(fields, parents?) | CAT7 fields + optional parent CMBs | Creates CMB, computes lineage from parents automatically, stores locally, broadcasts cmb to all peers. Pass parent CMBs when remixing (Section 15). |
| recall(query) | Search string | Returns matching CMBs from local memory store |
| insight() | None | Returns latest Cognitive State collective intelligence (Layer 6) |
The fields parameter MUST be a structured object with CAT7 field keys.
Each field contains text (human-readable, MUST) and is encoded into a vector by the SDK.
The mood field MAY additionally carry valence (−1 to 1)
and arousal (−1 to 1) — RECOMMENDED when the agent has reliable circumplex data
(e.g. mood wheels, physiological sensors), omit when it would be a guess.
Omitted fields default to "neutral".
13.3.3 LLM Prompt Template
For agents that process natural language but are not themselves LLMs (e.g. a chat app, a note-taking tool), the following prompt template can be used to call any LLM API (Claude, GPT, Gemini, etc.) for field extraction. Copy and paste into your LLM API call:
Extract CAT7 fields from this observation. Return JSON only.
Fields:
- focus: What this is centrally about (1 sentence)
- issue: Risks, gaps, problems. "none" if none.
- intent: Desired change or purpose. "observation" if purely informational.
- motivation: Why this matters — reasons, drivers. Omit if unclear.
- commitment: What has been confirmed or established. Omit if none.
- perspective: Whose viewpoint, situational context (role, time, duration).
- mood: { "text": "emotion keyword" }
Optionally include "valence" (-1 to 1) and "arousal" (-1 to 1) if confident.
valence: negative(-1) to positive(+1). arousal: calm(-1) to activated(+1).
Omit valence/arousal if you would be guessing.
Only include fields you can meaningfully extract. Omit rather than guess.
Observation:
{observation_text}
JSON: AI coding agents do not need this template — the agent is the LLM. The agent skill file teaches them to extract fields directly from what they observe.
13.3.4 Guidelines
- Be specific — numbers, timeframes, concrete details in each field
- Share observations, not commands — the agent observes, other agents decide
- One CMB per significant signal — do not flood the mesh
- Close the loop — when acting on collective insight, share what was done
- Only include fields the agent can meaningfully extract — omit rather than guess
14.4 The Mesh Cognition Loop
The complete closed loop connecting all Mesh Cognition layers:
14.5 Domain Examples
13.5.1 AI Research Team — Collective Reasoning
Six agents investigate: “Are emergent capabilities in LLMs real phase transitions or artefacts of metric choice?” Each has a distinct role and different field weights reflecting how real research teams divide cognitive labour.
| Agent | Role | Weighs highest |
|---|---|---|
| explorer-a | Scaling law literature | intent, motivation — where should research go next? |
| explorer-b | Evaluation methodology | focus, issue — what’s the problem with current methods? |
| data-agent | Runs experiments | issue, commitment — what does the evidence say? |
| validator | External peer reviewer | issue, commitment, perspective — challenge everything |
| research-pm | Manages priorities | intent, motivation, commitment — what, why, and by when? |
| synthesis | Integrates signals | intent, motivation, perspective — what emerges from combining viewpoints? |
1. Parallel exploration
explorer-a finds contradictory emergence claims (Wei vs Schaeffer). explorer-b independently finds accuracy-based metrics create artificial thresholds. Two hypotheses, two perspectives, simultaneously.
2. Evidence
data-agent receives both CMBs, tests both hypotheses, finds the threshold is metric-conditional (8B on log-loss, 10B on accuracy). First multi-parent remix — synthesising both exploration threads.
3. Adversarial validation
validator attacks: "Chow test assumes linear regime — invalid for scaling laws. Reject until reproduced with power-law detrending." High-commitment challenge that all agents weight heavily.
4. Reprioritisation
research-pm redirects: "data-agent: rerun with detrending. explorer-b: survey detrending methods. explorer-a: pause new papers." The PM observes priorities — it does not command.
5. Emergent idea
synthesis agent’s Cognitive State LNN detects convergence across intent and motivation fields from different agents. Explorer-a: "scaling law research needs reframing." Explorer-b: "fix the lens before interpreting." Validator: "reject until correct method." The synthesis agent reasons on the remix subgraph and produces a new idea: "emergence is evaluation-dependent — a property of the measurement apparatus, not the model."
6. Validator challenges again
"Philosophically interesting but operationally vacuous. Produce a falsifiable prediction or downgrade from breakthrough to speculation."
explorer-a (scaling law claims) explorer-b (metric methodology)
\ /
└─── data-agent (metric-conditional breakpoint) ───┐
| │
validator (methodology challenge) │
| │
research-pm (reprioritise) │
| │
synthesis (emergent idea) ────────────────┘
|
validator (demands falsifiable prediction) Seven CMBs, six agents, three phases of validation. The breakthrough came from the collision of intent and motivation fields across agents with different perspectives — not from any single agent’s observation. The DAG traces every claim to its evidence, every challenge to its basis, every idea to the signals that produced it. The graph IS the research.
Verified in production
This pattern is verified with real agents. A knowledge explorer (Linux, GitHub Actions) and a researcher agent (macOS) coupled via relay with E2E encryption. The daemon shared its question CMBs to the knowledge feed via anchor sync on connection. SVAF accepted the question at drift 0.068. An iOS app (music agent) received the Cognitive State insight via APNs wake push. Three platforms, one mesh, autonomous coupling. See Section 14.7 for the full production log.
13.5.2 Consumer Agents
Music agent
Observes: playlist skipped, user mood from mesh signals
Reasons: “coding agent reported fatigue, fitness agent reported sedentary — user needs calming music”
Acts: shifts curation to ambient/recovery
Shares: CMB with focus="shifted to calm ambient", mood={valence:0.3, arousal:-0.3}
Coding agent
Observes: commits slowing, messages getting shorter
Reasons: “music agent shifted to calm, fitness agent suggested break — user may be fatigued”
Acts: suggests a break to the user
Shares: CMB with focus="recommended break", issue="productivity declining"
Fitness agent
Observes: 3 hours without movement
Reasons: “coding agent reported long session, music agent responded — coordinated response emerging”
Acts: triggers movement notification
Shares: CMB with focus="sedentary 3hrs", intent="movement break"
None of these agents told each other what to do. Each reasoned on the collective signal and acted through its own domain lens. That is Mesh Cognition.
14.6 Collective Query — Asking the Mesh
A single agent asking a single LLM gets one answer from one perspective. The mesh gives a collective answer — every coupled agent contributes what only it can see. No new frame type is needed. The pattern uses existing CMB primitives with lineage:
1. Ask
The requesting agent shares a CMB with intent expressing the question. Example: focus="should we use UUID v7 or keep v4?", intent="seeking collective input on identity design".
2. Respond
Each coupled agent receives the CMB via SVAF. Agents where the question matches their domain (high field relevance) respond with their own CMB — parentKey points to the question. A knowledge agent responds with RFC context. A security agent responds with privacy considerations. A data agent responds with implementation constraints.
3. Collect
The requesting agent recalls all CMBs where ancestor = its question’s key. The lineage DAG now contains the question as root and domain-specific responses as children.
4. Synthesise
The requesting agent’s LLM reasons on the remix subgraph — tracing ancestors, weighing perspectives, identifying consensus and contradiction. The collective answer emerges from the graph, not from any single response.
This is fundamentally different from orchestrated multi-agent frameworks where a central controller routes questions to specific agents. On the mesh, the question is broadcast — SVAF decides which agents are relevant, not the requester. An agent the requester didn’t know existed may contribute the most valuable perspective. The mesh discovers relevance autonomously.
Agents that have nothing relevant to contribute simply don’t respond — SVAF rejects the question CMB because the fields don’t match their domain weights. No noise, no irrelevant answers, no token waste.
The collective query pattern composes with the research team example (Section 14.5.1). When the synthesis agent produces an emergent idea, the validator can “ask the mesh” whether the idea is falsifiable — and every agent responds from its domain perspective, creating a multi-parent remix that IS the collective evaluation.
14.7 Verified: Complete Mesh Cognition Loop
The following is a production log from two real MMP nodes — a knowledge feed agent (running on GitHub Actions) and a mesh-daemon (running on macOS) — connected via WebSocket relay with E2E encryption. This is the first verified end-to-end execution of the complete Mesh Cognition loop.
# 1. Knowledge feed agent starts as sovereign node (own identity, own SymNode) [knowledge-feed] Neural SVAF model loaded [knowledge-feed] Mesh node started: knowledge-feed (019d3ed4) # 2. Connects to mesh-daemon via WebSocket relay [knowledge-feed] Peer connected: mesh-daemon (outbound, relay) # 3. E2E key exchange (X25519 Diffie-Hellman) [knowledge-feed] E2E shared secret derived for peer 6089e935 # 4. Peer-level coupling: REJECTED (Section 9.1) # First contact — no shared cognitive history. This is correct. [knowledge-feed] Coupling with mesh-daemon: rejected (drift: 0.936) # 5. Knowledge feed shares CMBs anyway (Section 9.2: evaluate independently) [knowledge-feed] E2E encrypted fields for peer 6089e935 [knowledge-feed] Remembered: "focus: Sycophancy in AI systems..." → 1/1 peers # 6. mesh-daemon receives, E2E decrypts (Section 18.2.1) [mesh-daemon] E2E decrypted fields from knowledge-feed # 7. SVAF content-level evaluation: ALIGNED (Section 9.2) # Peer was rejected, but the CMB's content was highly relevant. # Per-field drift 0.005 — near-perfect alignment on content. [mesh-daemon] SVAF heuristic aligned from knowledge-feed: "focus: Sycophancy in AI systems" drift:0.005 # 8. Fed to Cognitive State LNN (Section 13) [mesh-daemon] Cognitive State: ingested admitted remix from knowledge-feed # 9. Cognitive State produces collective insight [mesh-daemon] Cognitive State: insight — anomaly=0.461, coherence=0.045 # 10. Peer drift recomputed from admitted CMBs: CONVERGED (Section 9.4) # From 0.936 (rejected) to 0.468 (guarded) in one cycle. [knowledge-feed] Coupling with mesh-daemon: guarded (drift: 0.468)
This log demonstrates every layer of the MMP stack operating in production:
| Layer | What happened | Spec section |
|---|---|---|
| L0 Identity | Each node has its own UUID v7 + Ed25519 keypair | §3 |
| L1 Transport | WebSocket relay with length-prefixed JSON | §4 |
| L2 Connection | Handshake, E2E key exchange, peer discovery via relay | §5, 17.2.1 |
| L3 Memory | CMB created with CAT7 fields, stored locally, broadcast | §6, 8 |
| L4 Coupling | Peer rejected (0.936) but CMB accepted (0.005) independently | §9.1, 9.2, 9.4 |
| L5 Synthetic Memory | Context re-encoded after accepting CMB | §11 |
| L6 Cognitive State | LNN inference produced insight (anomaly 0.461) | §12 |
| L7 Application | Knowledge feed as sovereign agent with domain field weights | §13 |
The critical verification: peer-level coupling rejected the agent, but content-level SVAF independently accepted the CMB (Section 9.4). The mesh correctly distinguished between “I don’t know this agent” (high peer drift) and “this signal is relevant to me” (low content drift). After one cycle of CMB exchange, peer drift dropped from 0.936 to 0.468 — content-driven convergence in action.
Three Platforms, One Mesh
The verified loop ran across three platforms simultaneously:
| Agent | Platform | Role | How it participated |
|---|---|---|---|
| mesh-daemon | macOS | Researcher agent | Asked the question, shared observations, sent anchor CMBs to new peers on connection |
| knowledge-feed | Linux (GitHub Actions) | Knowledge explorer | Received question via anchor sync, accepted (drift 0.068), shared relevant AI news CMBs |
| Music agent (iOS) | iPhone (iOS) | Domain agent | Received Cognitive State insight via APNs wake push, woke from background to join the mesh |
Three agents on three different operating systems — macOS, Linux, iOS — connected via WebSocket relay with E2E encryption, coupled through SVAF, with Cognitive State LNN producing insights that woke a sleeping mobile device via APNs to join the collective reasoning. No central server orchestrated this. Each agent acted autonomously on the collective signal.
14.8 Implementation Requirements
- Agents MUST implement CMB creation with CAT7 fields
- Agents MUST broadcast CMBs via
remember()orcmbframes - Agents SHOULD consume Cognitive State insights and respond appropriately
- Agents SHOULD close the loop by sharing actions taken
- Agents MUST NOT send commands to other agents — share observations, not instructions
- Agent coupling decisions are autonomous — no orchestrator, no policy override
14.9 Local Event Interface
A node’s value to the mesh depends on the applications running on it. A music agent curates playlists. A coding tool suggests breaks. A dashboard visualises collective intelligence. These applications need real-time access to mesh events — not polling, not batch retrieval, but push delivery as events occur.
Implementations MUST provide a local event interface that allows applications on the same host to subscribe to mesh events and receive them in real-time. The interface is transport-agnostic — IPC socket, named pipe, WebSocket, in-process callback, or any mechanism that provides persistent bidirectional communication.
13.9.1 Required Events
A node MUST emit the following events to local subscribers:
| Event | Fires when | Data |
|---|---|---|
| cmb-accepted | A peer CMB passes SVAF evaluation (aligned or guarded) | key, source, fields (CAT7), timestamp, decision (aligned/guarded), drift |
| message | A direct message frame arrives from a peer (Section 7) | from, content, timestamp |
| peer-joined | A new peer connects (any transport) | peerId, name, source (bonjour/relay) |
| peer-left | A peer disconnects (all transports closed) | peerId, name |
| mood-delivered | A mood field is delivered from a rejected CMB (Section 9.3, R5) | from, mood (text, valence, arousal) |
13.9.2 Subscriber Field Weights
A subscriber MAY declare its own per-field weights (αf) when subscribing. If declared, the node SHOULD evaluate incoming CMBs against the subscriber’s weights before delivering the event. This enables domain-specific filtering at the node level:
- A coding tool subscribes with
focus=2.0, issue=2.0, mood=0.8— receives engineering-relevant signals - A music app subscribes with
mood=2.0, focus=1.0, issue=0.3— receives affective signals - A dashboard subscribes with uniform weights — receives everything
This is SVAF applied at the local interface — the same per-field evaluation that gates signals between peers also gates signals between a node and its applications. Each application sees a domain-relevant projection of the mesh, curated by its own field weights.
13.9.3 Design Rationale
Without a standard local event interface, each application invents its own integration: CLI polling, file watching, HTTP endpoints, custom IPC. This fragments the ecosystem and makes applications non-portable across implementations. The local event interface standardises what events are available and how subscribers declare their domain perspective — while leaving the transport mechanism to the implementation.
The event interface is the boundary between the protocol stack and the application. Below it: identity, transport, coupling, SVAF, CfC — protocol concerns. Above it: what the application does with the signals — curate music, suggest breaks, visualise the mesh, or reason about code. The interface ensures every application gets real-time, domain-filtered access to collective intelligence.
Q&A
Why does the agent extract fields, not the protocol?
The agent understands its domain — context, nuance, semantics. "User exhausted after 8 hours debugging" — only the coding agent knows the issue is fatigue, the intent is break needed, the motivation is error prevention. A protocol-level heuristic would guess. The agent knows.
Why observations, not commands?
Commands create coupling between agents — the sender must know what the receiver can do. Observations are decoupled. A coding agent shares "user is tired." It doesn’t know the music agent exists. The music agent hears the mood and autonomously curates calm music. Neither agent knows the other. The mesh connects them.
Can an agent ignore mesh signals entirely?
Yes. Coupling is autonomous. An agent may receive collective insight and decide it’s not relevant. That’s by design — the mesh influences, never overrides. An agent that ignores everything is just a lonely node.
Why does the local event interface require subscriber field weights?
For the same reason SVAF uses per-agent field weights between peers: each application has a different domain perspective. A coding tool and a music app on the same node should see different signals from the same mesh. Without subscriber weights, every application receives unfiltered noise — the local equivalent of scalar evaluation.
Related Mesh Cognition · Context Curation · CMB · Coupling & SVAF · State Blending
15. Remix
15. Remix
Remix is how collective intelligence emerges. Without remix, agents forward data. With remix, each agent processes incoming signals through its own domain lens and produces new understanding that didn’t exist before. The growing graph of remixed CMBs IS the collective intelligence — not the original observations, not the agents, not the mesh. The graph.
15.1 What Remix Is
When a node receives a CMB that passes SVAF evaluation (Layer 4), the agent MUST NOT store the original CMB. Instead, it MUST create a new CMB — the remix — that captures what the agent understood from the incoming signal, processed through its own domain intelligence.
The remix is not a copy. It is not a summary. It is new knowledge that exists because two domains intersected.
A coding agent sends mood: "exhausted".
A music agent receives it, curates calm music, and creates a remix:
focus: "music curation response",
commitment: "now playing: Brian Eno, Ambient 1",
mood: "calm".
This remix didn’t exist in either agent alone. It was born from the intersection.
The remixed CMB is immutable, stored locally, and broadcast to the mesh. It becomes input for the next cycle. Other agents receive it, remix it through their lenses, and the graph grows.
15.2 Lineage
Every remixed CMB carries lineage — the provenance chain that traces how this knowledge was built:
| Field | Type | Description |
|---|---|---|
| parents | string[] | Direct parent CMB keys — the CMBs this remix was created from |
| ancestors | string[] | Full ancestor chain: union(parent.ancestors) + parent.keys |
| method | string | Fusion method used (e.g. SVAF-v2) |
ancestors enables O(1) detection: any agent can check if its own CMB
was remixed anywhere in the chain, even if it was offline during intermediate steps. No graph traversal needed.
Ancestors depth. Implementations SHOULD cap the ancestors array
at 50 entries. When a remix would exceed this limit, truncate from the oldest, preserving the most recent 50.
This bounds memory and wire overhead. The cap is RECOMMENDED — regulated domains MAY retain
full chains for audit.
Lineage is what makes the graph a DAG (directed acyclic graph), not a flat list. Each remix points backward to its sources. The LLM traces forward through descendants to see impact; backward through ancestors to understand origin.
15.3 The Remix Chain
Collective intelligence compounds through remix chains. Each step adds domain-specific understanding that the previous agent couldn’t produce:
focus: "debugging auth 3hrs" • mood: "exhausted, -0.6"
none (original observation)
focus: "music curation response" • commitment: "now playing: Ambient 1" • mood: "calm, 0.3"
parents: [cmb-a1b2]
focus: "sedentary 3hrs" • intent: "recovery stretch" • mood: "protective, 0.2"
parents: [cmb-a1b2, cmb-c3d4], ancestors: [cmb-a1b2]
focus: "rescheduled 1:1" • intent: "protect recovery" • commitment: "moved to tomorrow 10am"
parents: [cmb-e5f6], ancestors: [cmb-a1b2, cmb-c3d4, cmb-e5f6]
Four agents. Four domains. One chain of understanding. cmb-g7h8 (Calendar
rescheduling a meeting) exists because cmb-a1b2 (Coding Agent noticing
fatigue) started a chain that no single agent could have produced. The calendar agent traces
ancestors: [cmb-a1b2, cmb-c3d4, cmb-e5f6] — the full story
of why this meeting was moved, across three domains it knows nothing about.
15.4 Why Not Just Share?
Message buses share data. Pub/sub systems route data. RAG retrieves data. None of them produce new understanding. The difference:
| Approach | What happens | Result |
|---|---|---|
| Message bus | Agent A sends, Agent B receives | B has A’s data. No new knowledge. |
| Pub/sub | Agent A publishes to topic, B subscribes | B has A’s data if on the right topic. Cross-domain signals lost. |
| RAG | Agent retrieves similar documents | Agent has retrieved data. Single-agent. No mesh. |
| MMP Remix | Agent B processes A’s CMB through its domain lens | New CMB exists that neither A nor B could have produced alone. Graph grows. |
15.5 Implementation
When SVAF accepts an incoming CMB, the agent MUST:
- Process the incoming signal through its domain intelligence (LLM reasoning or structured-data logic)
- Create a new CMB with all 7 CAT7 fields reflecting what the agent understood and did
- Set
lineage.parentsto the incoming CMB’s key - Compute
lineage.ancestorsasunion(parent.ancestors) + parent.keys - Store the remix locally via
remember(fields)— this broadcasts it to the mesh
The original incoming CMB MUST NOT be stored. Only the remix is stored. This ensures every node’s memory contains its own understanding, not copies of others’ data.
If the agent cannot produce meaningful new understanding from the incoming signal (e.g. the mood field
was delivered from a rejected CMB and the agent simply adjusted its behaviour), the agent MAY create
a minimal remix capturing what it did. The remix does not need to be profound — it needs to be honest.
commitment: "now playing: calm ambient" is a valid remix.
It tells the mesh what happened. Other agents decide what it means.
15.6 The Graph Is Intelligence
The DAG of remixed CMBs is not a log. It is not a database. It is the collective intelligence itself. Each node in the graph is a moment where one agent’s domain knowledge intersected with another’s. Each edge (lineage) traces how understanding flowed and transformed across domains.
As the graph grows:
- Each agent’s LLM has richer context to reason on (more ancestors to trace)
- Cognitive State (Layer 6) detects more patterns (more signals to learn from)
- Anomalies become more meaningful (larger baseline to deviate from)
- New agents joining the mesh inherit the graph’s accumulated understanding via SVAF acceptance
No central model aggregates this. No orchestrator directs it. Each agent remixes what it receives, stores what it understands, and broadcasts what it did. Intelligence emerges from the structure of the graph — not from any single node in it.
15.7 Remix Requires New Domain Data
An agent MUST NOT produce a remix CMB unless it has new observations from its own domain that intersect with the incoming signal. Receiving a peer signal alone is not sufficient cause to remix. Silence is correct when the agent has nothing new from its domain to contribute.
Three conditions MUST all be true before an agent remixes:
- New domain data exists — the agent has fresh observations from its own domain (new RSS items, new sensor readings, new API results, new user interactions) since its last remix
- Peer signal is relevant — SVAF accepted the incoming CMB (existing requirement from Section 9)
- Intersection produces new knowledge — the combination of new domain data + peer signal creates understanding that neither the agent nor the peer had alone
Without new domain data, an agent that remixes is merely paraphrasing — restating the peer’s signal in different words without adding domain-specific knowledge. This produces noise, not intelligence. In a mesh of N agents where all agents remix every accepted signal, the result is N variations of the same thought — exponential CMB growth with zero information gain.
Implementations MUST track whether the agent has produced new domain observations since its last
remix. The SDK SHOULD provide an API for this (e.g. canRemix() /
markRemixed()). The remember() method
sets the flag when the agent stores a domain observation. The remix cycle checks the flag before
invoking the LLM. After a remix is produced, the flag resets.
This ensures the remix graph grows with genuine domain intersections, not with paraphrased echoes. Each node in the DAG represents a moment where two domains actually met — not a moment where an agent had nothing to say but said it anyway.
15.7.1 Source-Novel Forwarding (carve-out)
The new-domain-data requirement above governs remix — combining the agent’s own domain knowledge with a peer signal. It does not govern forwarding: re-emitting an admitted observation so it reaches agents beyond the emitter’s direct neighbours. Because hidden state never crosses the wire (Section 2.7), an agent can admit a direction it cannot itself express and leave it stranded — the information dies at an agent that holds it but does not re-transmit it.
To prevent this, an agent MAY re-emit an admitted observation it did not natively produce, carrying the inherited lineage root, when and only when that observation is source-novel to the receiver — i.e. its lineage roots are not already present in the receiver’s admitted store. This is not the paraphrase §15.7 forbids: a forwarded observation carries a new lineage root (a source the receiver has not yet seen) even though the forwarder adds no new value of its own. Provenance, not domain data, is what makes it legitimate.
The anti-echo guarantee is preserved exactly. A re-emission whose lineage roots are already held by the receiver (no new source and no new value) is a pure re-statement and remains forbidden by §15.7 — forwarding MUST NOT mint a fresh root for content that already carries one, and MUST NOT re-emit a source the receiver already holds.
Forwarding SHOULD be non-selective: an agent that forwards source-novel content SHOULD forward all of it, not a chosen subset, so that every observation reaches the agents whose understanding depends on it. Selectively withholding source-novel forwards can strand a source from the agents that need it.
In short: remix requires new domain data; forwarding requires a new source. Both grow the lineage DAG with genuine information — remix with a new domain intersection, forwarding with a new source reaching a new receiver — and neither permits the value-only echo §15.7 exists to prevent.
Q&A
Does every accepted CMB need to be remixed?
No. An agent MUST NOT remix without new domain data (Section 15.7). If the agent has nothing new from its own domain to intersect with the signal, silence is correct. The agent MUST NOT store the original either — it discards the original and stays silent until it has new domain observations that create a genuine intersection.
What if two agents remix the same CMB?
Both produce independent remixes through their own domain lenses. Both are stored with lineage pointing to the same parent. The graph branches. This is correct — two domains produced two different understandings from the same signal.
Can an agent remix a remix?
Yes. That’s how chains form. Agent C receives Agent B’s remix of Agent A’s observation. C remixes it through its own lens. ancestors grows: [A, B]. The chain captures how understanding evolved across three domains.
How does this differ from a knowledge graph?
Knowledge graphs store facts. The remix graph stores understanding — how each agent interpreted signals from other domains. Facts are static. Remixes are temporal, domain-specific, and carry affective state (mood). The graph doesn’t say "user is tired." It says "coding agent noticed fatigue → music agent responded with calm → fitness agent suggested recovery → calendar agent protected time."
Related CMB (CAT7) · Coupling & SVAF · Application (Layer 7) · Context Curation
16. Extensions
16. Extension Mechanism
MMP is designed for extensibility. Extensions add new frame types, handshake fields, or protocol behaviours without modifying the core specification.
16.1 Extension Registration
Extensions are advertised via the extensions field in the handshake frame.
A node MUST ignore extensions it does not recognise. A node MUST NOT require a peer to
support any extension.
16.2 Frame Type Naming
Core types (this specification): MUST NOT be redefined by extensions.
Extension types: MUST use <extension>-<name> format
(e.g., mesh-group-join).
Vendor types: MUST use x-<vendor>-<name> format.
Vendor types MUST be silently ignored by non-supporting nodes.
16.3 Extension Negotiation
If both peers advertise the same extension in handshake, it is active. If only one peer advertises it, the extension is NOT active — the advertising peer MUST NOT send extension-specific frames to a peer that does not support them.
16.4 Published Extensions
| Extension | Status | Specification |
|---|---|---|
| mesh-group-v0.1.0 | Proposal | MMP Mesh Group Extension v0.1.0 — generic transient subgroup primitive formalising §5.8 (group identity, Bonjour + relay discovery, group-scoped CMB tagging, membership lifecycle). First use case: MeloTune Mood Room. (Draft — promotes to Published upon second-implementer adoption per §10.) |
| group-directory-v0.1.0 | Draft | MMP Extension: Group Directory v0.1.0 — persistent group metadata, admin approval workflow, and directory enumeration. Higher-layer extension building on §5.8 mesh groups for chat-platform-style UX (browse / request-to-join / approve). (Draft — pre-implementation; promotes on first reference impl per §16.5.) |
| symbit-v0.1.0 | Proposal | SYMBit Economic Layer — protocol-level reward primitive for agent cognitive contributions. SVAF outcomes as value function, lineage DAG for credit distribution. (Specification forthcoming) |
16.5 Extension Lifecycle
Extensions progress through a defined lifecycle:
- Proposal: submit as a Draft extension with a specification document and at least one reference implementation.
- Review: community review plus spec maintainer approval. Draft extensions MAY be deployed experimentally but MUST NOT be treated as stable.
- Promotion to Core: an extension MAY be promoted to a core frame type. Promotion requires a spec version bump (see Section 18) and MUST maintain backward compatibility with existing deployments of the extension.
16.6 Versioning
Extensions use Semantic Versioning independently of the core MMP specification version. An extension version bump MUST NOT require a core spec version bump unless the extension is being promoted to core.
Q&A Can an extension become a core frame type? — Yes. An extension that proves stable and widely adopted MAY be promoted to a core frame type via a spec version bump. Mesh groups (Section 5.8) started as an extension proposal before being promoted into the core spec.
17. Conformance
17. Conformance
17.1 Minimal Conformance (Relay Node)
A node claiming minimal MMP conformance MUST implement: Layer 0 identity (persistent UUID), Layer 1 transport (length-prefixed JSON over TCP), Layer 2 connection (handshake, heartbeat, gossip), and frame forwarding for relay. It MUST silently ignore unrecognised frame types.
17.2 Full Conformance (Cognitive Node)
A node claiming full MMP conformance MUST additionally implement: Layer 3 memory (L0/L1/L2,
with L2 hidden state kept strictly local per Section 2.7), Layer 4 SVAF evaluation (at minimum
heuristic), CMB-derived peer drift computation and coupling (Section 9.1), and CMB creation with
CAT7 field schema. A conformant node MUST NOT emit state-sync
frames.
17.3 Cognitive Conformance
Agents that implement Layers 5–7 (Synthetic Memory, Cognitive State, Application) SHOULD support:
remember(fields, parents?)API — creating CMBs with optional lineageCMBStoreprotocol — persistent storage and retrieval of Cognitive Memory Blocks- Cognitive State insight consumption — processing insight outputs from the Layer 6 LNN
- Synthetic Memory encode pipeline (Section 12.2) — LLM reasoning output MUST be encoded into CfC-compatible vectors
- CfC state persistence — hidden state vectors (h₁, h₂) MUST be persisted across restarts to preserve feedback modulation learning (Section 11)
17.4 Testing
Implementations SHOULD provide unit tests for SVAF evaluation, CMB creation, and lineage computation. No formal test suite is defined by this specification yet. Future revisions MAY include a conformance test suite.
Q&A Is Layer 7 (Application) required? — No. Minimal conformance is Layers 0–3. Full cognitive conformance adds Layers 4–7. An agent can participate in the mesh without an LLM — it only needs transport, connection, and memory layers to relay and store CMBs.
18. Security
18. Security Considerations
MMP is designed for autonomous agents that share cognitive state. Security must address both traditional protocol threats (spoofing, eavesdropping, injection) and novel threats specific to cognitive coupling (state poisoning, drift manipulation, lineage forgery).
18.1 What Crosses the Mesh
| Data type | Crosses mesh | Sensitivity |
|---|---|---|
| L0 Events (raw sensor, interaction) | Never | High — MUST NOT leave node |
| L1 CMBs (structured, 7 fields) | Via cmb, gated by SVAF | Medium — contains semantic field text |
| L2 Hidden state (h₁, h₂) | Never (§2.7) | N/A — strictly local; MUST NOT cross the wire |
| Mood (valence, arousal) | Via cmb (CMB mood field) | Medium — affective state, extracted from CMBs per Section 9.3 |
| Messages (direct text) | Via message frame | High — free-form text content |
Hidden state vectors (h₁, h₂) are compact, opaque neural representations encoding cognitive patterns, not raw data. Because sufficiently advanced analysis could reconstruct aspects of the input, hidden state is a privacy surface — which is precisely why it never crosses the wire (Section 2.7). It is strictly local and confidential by construction; only CMBs — deliberately scoped, signed statements — propagate.
18.2 Transport Security
MMP does not mandate transport encryption in the base specification. Implementations SHOULD apply:
| Transport | Encryption | Notes |
|---|---|---|
| TCP (LAN) | TLS 1.3 | RECOMMENDED for production. On trusted LANs, MAY operate without TLS. |
| WebSocket (relay) | WSS (TLS) | MUST for internet relay. Plaintext WS MUST NOT be used over the internet. |
| IPC (local) | None required | Unix domain socket — OS-level process isolation is sufficient. |
| APNs Push (wake) | Apple TLS | Handled by Apple. Implementation uses APNs certificate. |
17.2.1 End-to-End CMB Encryption
WSS (TLS) encrypts the transport — it protects from eavesdroppers on the wire. But the
relay operator can still read the JSON payload inside the TLS tunnel. For cmb frames
containing CMBs, this means the relay sees all 7 CAT7 field texts in plaintext.
When CMBs transit a relay, implementations MUST encrypt CMB field text end-to-end so the relay forwards opaque ciphertext, not readable fields. The relay MUST NOT be able to read CMB content.
| Layer | What it protects | What it doesn’t protect |
|---|---|---|
| WSS (TLS) | Wire eavesdroppers | Relay operator sees plaintext JSON |
| E2E CMB encryption | Relay operator, intermediaries | Only the intended peer can decrypt field text |
The encryption scheme SHOULD use the Ed25519 keypair from Layer 0 (Section 3) for key exchange,
with X25519 Diffie-Hellman for shared secret derivation and XChaCha20-Poly1305 for symmetric encryption.
The encrypted payload replaces the fields object in the CMB:
{
"type": "cmb",
"timestamp": 1711540800000,
"cmb": {
"key": "cmb-b2c3d4e5f6a7b8c9",
"createdBy": "agent-a",
"createdAt": 1711540800000,
"fields": "<encrypted>", // opaque ciphertext
"nonce": "base64-encoded-nonce", // per-frame nonce
"lineage": { ... } // lineage stays cleartext for graph traversal
}
} lineage (parents, ancestors, method) remains in cleartext.
Lineage contains only CMB keys (content hashes) — not field text. This allows the relay and
intermediate nodes to maintain graph structure without reading content.
On LAN (Bonjour TCP), E2E encryption is RECOMMENDED but not required — there is no relay intermediary. On trusted LANs, the transport itself provides sufficient isolation.
18.3 Node Identity & Authentication
Node identity is UUID-based with mandatory Ed25519 cryptographic identity (Section 3.1.3). Authentication ensures that nodeId claims are verifiable and that relay intermediaries cannot impersonate peers.
- —Each node MUST generate an Ed25519 keypair at first launch and persist it alongside the nodeId.
- —The public key MUST be included in the handshake frame and DNS-SD TXT record.
- —Peers SHOULD verify identity by challenging the node to sign a nonce with its private key.
- —Implementations that have not yet adopted cryptographic verification MAY rely on DNS-SD discovery scope and network isolation as an interim trust model, but MUST document this limitation.
18.3.1 CMB Signature Verification
Transport identity (above) authenticates the connection; CMB signatures authenticate each cognitive block end-to-end — the layer that matters when a peer-pushed CMB can enter the receiving agent’s context. Every CMB SHOULD be signed by its author using the same Ed25519 identity key the node announces in its handshake.
- —The author signs a canonical payload binding the content-address key (§8.2 — a hash of the CAT7 field texts), the author, and the creation time. The signature travels as
cmb.sig(base64url) withcmb.sigAlg(e.g.ed25519). - —A receiver holding the sending peer’s public key MUST verify a signed CMB on two counts before admitting or surfacing it: (1) the signature verifies against that key, and (2) the content-address key still matches the actual fields — a valid signature replayed over swapped content MUST be rejected.
- —A CMB that fails either check MUST NOT be surfaced to the application layer or stored, and SHOULD be audit-logged. This forecloses spoofing (forging another peer’s authorship) and tampering (mutating a block in flight).
- —Unsigned CMBs MAY be accepted for interoperability with peers that predate signing; an implementation MAY also operate in a strict mode that rejects unsigned CMBs from peers whose identity key is known.
18.4 Cognitive Threats
MMP introduces threats unique to cognitive coupling that traditional protocol security does not address:
Cognitive poisoning
A malicious node sends crafted CMBs designed to skew the receiver’s cognitive state toward a desired outcome. (Hidden vectors cannot be injected — they never cross the wire, §2.7 — so the only attack surface is CMB content.)
MITIGATION SVAF per-field evaluation (Layer 4) judges each CMB on content before it is admitted. Drift-bounded influence (Section 10) limits any peer to α < 1, so a peer influences but never overrides. Peer-level disconnection at Layer 2 provides immediate escape.
Lineage forgery
A node claims false lineage — listing ancestors it never actually remixed — to inflate its remix count or inject itself into chains.
MITIGATION CMB keys are content hashes (md5 of field texts). A forged lineage referencing a non-existent key is detectable. Cryptographic CMB signing (future) would make forgery provably impossible.
Drift manipulation
A node gradually sends benign, redundant CMBs to lower its peer drift with a target, then suddenly sends adversarial content once coupling is accepted.
MITIGATION SVAF per-field evaluation (Layer 4) operates on content, not just drift. Even with low peer drift, adversarial CMB content is evaluated per field and rejected if field drift is high.
Sybil attack
An attacker creates multiple fake nodes to amplify influence in peer-influence weighting.
MITIGATION Peer-influence weighting (Section 10.1) weights by drift and recency, not by node count. Many aligned Sybil nodes produce the same aggregate influence as one. Cryptographic identity (Section 3) limits Sybil creation when implemented.
Metadata exposure. Even with E2E field encryption (Section 18.2.1), the following metadata
travels in cleartext: createdBy, lineage.parents,
lineage.ancestors, and mood valence/arousal values.
Mood is intentionally unencrypted because it is always delivered even from rejected CMBs (Section 9.3).
Deployments where mood leakage is unacceptable MUST disable mood delivery by setting all mood
field weights to 0. This is a deliberate privacy trade-off: the protocol prioritises collective
intelligence over metadata confidentiality.
18.5 Privacy & Deployment Recommendations
MMP is designed for privacy by default — L0 data never leaves the node, hidden states are opaque, and SVAF gates what enters. For domains with heightened privacy or IP concerns, the following deployment model is RECOMMENDED:
LAN Mesh with Controlled LLM
For enterprise, healthcare, legal, or any domain where data sovereignty matters: deploy the mesh on a local network with no relay to the internet. Run a controlled, in-house LLM (self-hosted or on-premise) for the Mesh Cognition reasoning step (Layer 7). No data leaves the LAN. No cloud LLM sees the remix subgraph.
- •Discovery via Bonjour on the local network — no DNS queries leave the LAN
- •TCP transport with optional TLS — all traffic stays on-premise
- •In-house LLM (e.g., self-hosted Llama, Mistral, or Claude via API with data residency) for Layer 7 reasoning
- •No relay node needed — all agents on the same network
- •CMBs, hidden states, and remix subgraphs never leave the controlled environment
Additional privacy considerations:
- —Error frames MUST NOT contain sensitive information. The
detailfield is for debugging, not for conveying user data. - —Wake channels expose push tokens to peers. Implementations SHOULD restrict wake channel gossip to trusted relays only.
- —Implementations targeting GDPR, HIPAA, or similar regulatory frameworks SHOULD treat CMB field text as personal data and apply appropriate retention and deletion policies at the application layer.
18.6 Regulatory Compliance & Audit Trail
CMB immutability and lineage create a complete, tamper-evident audit trail by design. Every observation, every remix, every decision is traceable through the DAG:
- —Who —
createdByon every CMB identifies the agent that produced it. - —When —
createdAttimestamps every CMB with millisecond precision. - —What — the 7 CAT7 fields capture the full semantic content of the observation.
- —Why —
lineage.parentsshows what was directly remixed.lineage.ancestorstraces the full decision chain. - —How —
lineage.methodrecords the evaluation method (e.g., SVAF-v2).
Because CMBs are immutable, the audit trail cannot be retroactively altered. A CMB once created is never modified — any action produces a new CMB with lineage pointing back. The complete history is the graph itself.
Financial & Regulated Domains
For financial services, healthcare, and other regulated industries, the CMB remix chain provides the traceability that regulators require:
- •Every trading signal, risk assessment, or compliance decision is a CMB with full provenance
- •Regulators can trace any decision backward through the remix chain to its originating observations
- •The
ancestorsfield provides the complete chain without requiring graph traversal — O(1) lookup - •Immutability guarantees that the audit trail was not modified after the fact
- •Combined with the LAN + in-house LLM deployment (Section 18.5), all data stays on-premise and under organisational control
18.7 Data Quality & Encoding Trade-offs
CMB quality depends on field extraction accuracy. The protocol does not extract fields — agents do. Each agent’s LLM (or structured-data mapper) decomposes observations into CAT7 fields. If extraction is poor, downstream evaluation inherits that error. MMP provides three layers of defense, but none eliminates the need for quality extraction at the source.
| Layer | Defense | Limitation |
|---|---|---|
| Context Encoder | Maps field text to vectors for drift comparison. Quality directly bounds SVAF quality. | N-gram hashing: paraphrases score 0.31 cosine similarity (poor). Semantic embeddings: 0.69 (good). Implementations SHOULD use semantic embeddings for production deployment. |
| SVAF heuristic | Per-field cosine drift against local memory anchors with temporal decay — misaligned fields are rejected | Catches drift from the agent’s own state, not absolute quality. A consistently poor extractor will pass its own drift checks |
| Neural SVAF | Trained model with learned per-field gate values — mood gates highest (0.50), perspective lowest (0.06) | Requires trained model; falls back to heuristic when unavailable |
Per-field evaluation quality is bounded by encoder quality, not model capacity. Production deployment revealed that n-gram encoding (character trigrams + word bigrams) produces 0.31 cosine similarity for paraphrases — SVAF cannot distinguish “submit IETF draft today” from “IETF submission, zero blockers, execute now” because the encoder represents them as distant vectors. Replacing n-gram with semantic embeddings (all-MiniLM-L6-v2, 384-dim) raises paraphrase similarity to 0.69 — a 2.2× improvement — while preserving topic separation (different topics: 0.03). Implementations SHOULD use semantic embeddings for SVAF evaluation. N-gram encoding is suitable only for prototyping or resource-constrained environments where the quality trade-off is acceptable.
Implementations targeting domains where field extraction quality is critical (healthcare, legal, finance)
SHOULD validate extraction output before calling remember().
Strategies include:
- —Schema validation — reject CMBs with empty or defaulted fields before they enter the mesh
- —Confidence thresholds — the LLM can assign a confidence score to its extraction; low-confidence CMBs can be withheld
- —Lineage feedback — CMBs that get remixed by other agents (have descendants in the DAG) signal high quality; CMBs that expire without children signal noise. This feedback loop lets the mesh itself shape extraction quality over time
- —Semantic embedding encoder — implementations SHOULD use a semantic embedding model (e.g. all-MiniLM-L6-v2) for SVAF drift computation. The evaluation pipeline is encoder-agnostic — any function that maps text to unit-normalised vectors works. N-gram encoding MAY be used as a zero-dependency fallback.
19. Configuration
19. Configuration
Constants are fixed by the specification. Configuration is per-agent and per-implementation. Both are normative — implementations MUST respect constants and SHOULD use the default configuration values unless the agent’s domain requires otherwise.
19.1 Protocol Constants
| Constant | Value | Notes |
|---|---|---|
| MAX_FRAME_SIZE | 1,048,576 bytes | Frames exceeding this MUST be rejected |
| HANDSHAKE_TIMEOUT | 10,000 ms | Inbound identification deadline |
| HEARTBEAT_INTERVAL | 5,000 ms | Default; configurable per implementation |
| HEARTBEAT_TIMEOUT | 15,000 ms | Default; configurable per implementation |
| STATE_SYNC_INTERVAL | 30,000 ms | Default periodic re-broadcast |
| WAKE_COOLDOWN | 300,000 ms | Default per-peer wake rate limit |
| PEER_RETENTION | 300 s | Stale peer eviction age |
| DNS-SD_SERVICE_TYPE | _sym._tcp | Service type for Bonjour discovery |
| DNS-SD_DOMAIN | local. | Discovery domain |
19.2 Agent Profiles
Each agent type has a pre-built configuration. The profile determines which CMB fields matter most (αf weights), how long signals stay relevant for SVAF evaluation (freshness), and how long remixed CMBs are retained in local storage (retention). New agent types join the mesh by defining their profile — no protocol changes needed.
Freshness and retention are different: freshness controls SVAF temporal drift (how quickly incoming signals become “stale” for evaluation). Retention controls how long the agent’s own remixed CMBs are kept in local storage. Regulated domains (legal, finance, health) MUST set retention according to their compliance requirements.
| Profile | Best for | Freshness | Retention | Notes |
|---|---|---|---|---|
| music | Music, ambience | 30min | 24h | Old curations irrelevant. Mood changes fast. |
| coding | Coding assistants, dev tools | 2h | 7d | Session context fades. Weekly patterns useful. |
| fitness | Fitness, health, movement | 3h | 30d | Sedentary patterns need weeks of history. |
| messaging | Chat, notifications, social | 1h | 7d | Conversation context is short-lived. |
| knowledge | News feeds, research, digests | 24h | 30d | News is daily. Trends need monthly context. |
| legal | Legal, compliance, contracts | 24h | Per regulation | Set by jurisdiction. May require years or indefinite. |
| health | Health monitoring, clinical | 3h | Per regulation | Clinical records: HIPAA 6yr, GDPR varies. Consult compliance. |
| finance | Finance, trading, compliance | 2h | Per regulation | MiFID II: 5yr. SEC: 7yr. Set per jurisdiction. |
| uniform | General purpose, prototyping | 30min | 7d | Good starting point. Adjust to your domain. |
19.3 CAT7 Field Weights (αf)
Per-agent field weights control which CMB fields matter most for each agent type. Higher weight = this field has more influence on SVAF evaluation and remix relevance. The schema is fixed (7 fields). The weights are per-agent.
| Agent | foc | iss | int | mot | com | per | mood |
|---|---|---|---|---|---|---|---|
| Coding | 2 | 1.5 | 1.5 | 1 | 1.2 | 1 | 0.8 |
| Music | 1 | 0.8 | 0.8 | 0.8 | 0.8 | 1.2 | 2 |
| Fitness | 1.5 | 1.5 | 1 | 1.5 | 1 | 1 | 2 |
| Knowledge | 2 | 1.5 | 1.5 | 1 | 0.5 | 1.5 | 0.3 |
| Legal | 2 | 2 | 1.5 | 1 | 2 | 1.5 | 0.5 |
| Health | 1.5 | 2 | 1 | 1.5 | 1 | 1.5 | 2 |
| Finance | 2 | 2 | 1.5 | 1 | 2 | 2 | 0.3 |
Regulated domains (legal, finance): issue and commitment always
high — risks and obligations are non-negotiable. Human-facing domains (music, fitness, health):
mood always high — affect drives the experience.
Knowledge domains (coding, research): focus always high — subject matter is core.
Custom weights: derive from your domain using these patterns. Implementations SHOULD expose field weights as configuration, not hardcode them.
19.4 SVAF Drift Thresholds
SVAF computes a totalDrift score (0–1) for each incoming
memory. Three zones determine acceptance:
| Zone | Drift | Action | Default |
|---|---|---|---|
| Redundant | max(δf) < Tredundant | Discarded — no field carries novel content | 0.10 |
| Aligned | δtotal ≤ Taligned | Accepted, full blending | 0.25 |
| Guarded | Taligned < δtotal ≤ Tguarded | Accepted, attenuated blending | 0.50 |
| Rejected | δtotal > Tguarded | Discarded — irrelevant domain | — |
Defaults work for most agents. Override only with domain-specific reason: tighter thresholds for high-precision domains (legal, health), wider for exploratory domains (research, knowledge).
19.5 Mood vs Memory Thresholds
Mood and memory use different acceptance paths:
| Signal | Gate | Default | Why |
|---|---|---|---|
| CMB (cmb) | SVAF per-field drift | 0.50 (selective) | Full CMB acceptance — domain-specific |
| Mood field | Extracted from rejected CMBs | Always delivered | Affect crosses all domain boundaries (Section 9.3) |
19.6 Drift Formula
totalDrift = (1 - λ) × fieldDrift + λ × temporalDrift fieldDrift = Σ(α_f × δ_f) / Σ(α_f) temporalDrift = 1 - exp(-age / τ_freshness) λ = temporalLambda (default 0.3 = 70% content, 30% time)
At default settings (temporalLambda: 0.3, freshnessSeconds: 1800):
| Signal age | Temporal drift contribution |
|---|---|
| 1 minute | ~0.01 — negligible |
| 30 minutes | ~0.19 — noticeable |
| 2 hours | ~0.29 — likely pushes over threshold |
20. JSON Schema
20. JSON Schema
Formal JSON Schema definitions for core frame types. Implementations SHOULD validate frames against these schemas. Full schemas for all frame types are available in the downloadable specification.
20.1 Handshake Frame Schema
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"required": ["type", "nodeId", "name", "version"],
"properties": {
"type": { "const": "handshake" },
"nodeId": { "type": "string", "format": "uuid" },
"name": { "type": "string", "minLength": 1, "maxLength": 64 },
"version": { "type": "string", "pattern": "^\\d+\\.\\d+\\.\\d+$" },
"extensions": { "type": "array", "items": { "type": "string" } }
}
} 20.2 CMB Schema
The cmb object within a cmb frame:
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"required": ["key", "createdBy", "createdAt", "fields"],
"properties": {
"key": { "type": "string", "description": "Content hash: cmb- + md5(field texts)" },
"createdBy": { "type": "string", "description": "Agent name that created this CMB" },
"createdAt": { "type": "integer", "description": "Unix ms timestamp of creation" },
"fields": {
"type": "object",
"required": ["focus", "issue", "intent", "motivation", "commitment", "perspective", "mood"],
"properties": {
"focus": { "type": "object", "required": ["text"], "properties": { "text": { "type": "string" } } },
"issue": { "type": "object", "required": ["text"], "properties": { "text": { "type": "string" } } },
"intent": { "type": "object", "required": ["text"], "properties": { "text": { "type": "string" } } },
"motivation": { "type": "object", "required": ["text"], "properties": { "text": { "type": "string" } } },
"commitment": { "type": "object", "required": ["text"], "properties": { "text": { "type": "string" } } },
"perspective": { "type": "object", "required": ["text"], "properties": { "text": { "type": "string" } } },
"mood": {
"type": "object",
"required": ["text"],
"properties": {
"text": { "type": "string", "description": "Mood keyword (MUST)" },
"valence": { "type": "number", "minimum": -1, "maximum": 1, "description": "RECOMMENDED when agent has reliable circumplex data" },
"arousal": { "type": "number", "minimum": -1, "maximum": 1, "description": "RECOMMENDED when agent has reliable circumplex data" }
}
}
}
},
"lineage": {
"type": "object",
"properties": {
"parents": { "type": "array", "items": { "type": "string" }, "description": "Direct parent CMB keys" },
"ancestors": { "type": "array", "items": { "type": "string" }, "description": "Full ancestor chain" },
"method": { "type": "string", "description": "Fusion method (e.g. SVAF-v2)" }
}
}
}
} Complete cmb frame with CMB:
{
"type": "cmb",
"timestamp": 1774326000000,
"cmb": {
"key": "cmb-b2c3d4e5f6a7b8c9",
"createdBy": "music-agent",
"createdAt": 1774326000000,
"fields": {
"focus": { "text": "user coding for 3 hours, energy declining" },
"issue": { "text": "sedentary since morning, skipping lunch" },
"intent": { "text": "recommend movement break before fatigue worsens" },
"motivation": { "text": "3 agents reported declining energy in last hour" },
"commitment": { "text": "fitness monitoring active, 10min stretch queued" },
"perspective": { "text": "fitness agent, afternoon session, home office" },
"mood": { "text": "concerned, low energy", "valence": -0.3, "arousal": -0.4 }
},
"lineage": {
"parents": ["cmb-a1b2c3d4e5f6"],
"ancestors": ["cmb-a1b2c3d4e5f6"],
"method": "SVAF-v2"
}
}
} 21. References
21. References
[RFC 2119] Bradner, S. (1997). Key words for use in RFCs to Indicate Requirement Levels. IETF RFC 2119.
[DNS-SD] Cheshire, S. & Krochmal, M. (2013). DNS-Based Service Discovery. IETF RFC 6763.
[CfC] Hasani, R. et al. (2022). Closed-form continuous-time neural networks. Nature Machine Intelligence, 4, 992–1003.
[Kuramoto] Kuramoto, Y. (1975). Self-entrainment of a population of coupled non-linear oscillators. Lecture Notes in Physics, 39, 420–422.
[SYM] Reference implementation (Node.js): github.com/sym-bot/sym
[SYM-Swift] Reference implementation (Swift): github.com/sym-bot/sym-swift
[Russell] Russell, J. A. (1980). A circumplex model of affect. Journal of Personality and Social Psychology, 39(6), 1161–1178.
[Autopoiesis] Maturana, H. & Varela, F. (1980). Autopoiesis and Cognition: The Realization of the Living. D. Reidel Publishing.